




➡️ Intro
안녕하세요, 케빈입니다.
블로그를 오픈한지 얼마 되지도 않았는데, 벌써 계획과 다른 방향으로 나아가는 게 아니냐(블로그 소개 글 참고) 우려를 표명하실 수 있으리라 생각하실 수 있습니다. 계획에 포함되어 있지 않을 뿐이지, 이런 리뷰 포스트를 아예 쓰지 않겠다고 한 것은 전혀 아니었으니, 부디 양해해 주시길 바랍니다. (당연히 다른 글도 올릴 겁니다. 쓸 글이 산더미예요.) 수업을 듣거나, 온라인 강의를 수강하거나, 컨퍼런스에 참석하거나, 동아리에 참여한 경우에도, 조금씩 써내려갈 생각입니다. 물론 인트로 포스트에서 얘기한 시리즈들과는 다르게 ‘온전한 형태의 비정기’ 연재가 될 것임은 자명합니다.
뜬 구름 잡는 이야기는 과감히 각설하고, 이 공간에서 다룰 내용은 ’컨퍼런스 리뷰‘입니다. 무려 글쓴이가 사회인이던 시절(그래봤자 고작 4달 전 이야기지만)에 다녀온 것이라, 매우 늦은 감이 없지 않아 있지만, 그래도 개인 노션에 후기를 Raw한 형태로라도 정리해 두었으니, 정돈된 형태로 다듬어 보자는 결심에서 공유해 봅니다.
지난 4월 25일, 판교 인프랩 오피스에서, 저녁 6시 30분부터 두 시간 가량 진행된, ”인프런 퇴근길 밋업 with KotlinConf’23 Global“에 대한 짤막한 소감과 코틀린(Kotlin)이라는 언어의 현재와 미래에 대한 제 생각들을 중심으로 이야기 나누어 보겠습니다.
함께 가시죠.
🧑🏻💻 What is Kotlin?
컬러풀하고 거대한 K.
이 파트에서는 Kotlin Programming Language Official Site 에서 언급하는 내용들과
영문 위키피디아: Kotlin(Programming Language)를 번역하고 요약해 작성했습니다.
한 언어의 미래에 대해 논하려면, 먼저 과거와 현재를 알아야겠지요. 우선 Kotlin FAQ(Frequently Asked Questions) 페이지에 언급된, ’Kotlin이 무엇이냐‘라는 질문에 대한 답을 살펴보도록 하겠습니다.
Kotlin is an open-source statically typed programming language that targets the JVM, Android, JavaScript, Wasm, and Native.
It's developed by JetBrains.
The project started in 2010 and was open source from very early on.
The first official 1.0 release was in February 2016.
Kotlin은 오픈소스 정적 타입 언어로서, JVM(Java Virtual Machine), 안드로이드, 자바스크립트, 웹어셈블리, 네이티브를 타겟으로 지원합니다.
Jetbrains 사에 의해 개발되었으며, Kotlin 프로젝트는 2010년에 첫 발걸음을 떼었습니다.
1.0 버전의 공식 배포는 2016년 2월에 이루어졌습니다.
답변을 찬찬히 뜯어보면, 크게 두 가지 지점에서 눈길이 멈춥니다.
’정적 타입(Statically Typed)’ 그리고 수많은 ’타겟‘.
먼저 정적 타입에 대한 이야기입니다. Kotlin은 Java를 기반으로 출발한 언어답게, 강한 Type-Safety(타입 안정성)를 추구합니다. 정적 타입의 언어는 컴파일 시에 변수의 타입을 결정합니다. (이와 반대로 JavaScript와 같은 동적(Dynamically-Typed) 언어는 런타임 시에 변수의 타입이 결정됩니다.) 여기에서 조금 더 개념을 확장해, 바인딩(Binding)에 대한 이야기로 넘어가 보죠.
| 코틀린은 동적 바인딩보다 정적 바인딩을 더 선호한다 |
코틀린은 타입 안전한, 합성적인 코딩 스타일을 장려한다. 확장 함수는 정적으로 바인딩된다.
기본적으로 클래스는 확장될 수 없고, 메서드는 다형적이지 않다.
여러분은 명시적으로 다형성과 상속을 활성화해야 한다.
덩컨 맥그레거, 냇 프라이스, 오현석 역,『자바에서 코틀린으로(Java to Kotlin: A Refactoring Guidebook)』(2021), 한빛미디어, 2022, p.30.
프로그래밍 세계에서 바인딩은 간단하게 ’호출과 본문의 연결(Association of method call to the method body)’이라고 정의할 수 있습니다. (원래는 ‘묶다’라는 의미로 널리 알려져 있지요.) Kotlin이라는 언어에서 정적 바인딩을 선호한다는 것은 크게 두 가지 의미를 지닙니다.
- 기본적으로 Class는 상속을 지원하지 않습니다. Overriding도 마찬가지입니다.
(
open키워드를 추가하지 않으면,final로 설정됩니다.) - Method Overriding은 컴파일 타임(JVM 기준, .kt 코드가 .class 바이트코드로 바뀔 때)이 아니라, 런타임에 이루어집니다. ( Runtime Polymorphism 에 대한 이해가 필요합니다. )
Polymorphism (다형성) 과 Binding 에 대한 이야기는 “[Android: Architecture #1] 객체지향이 뭔가요?” 와 추후 포스트에서 조금 더 다뤄보기로 하고, 여기서는 Kotlin이 “타입 안정성” 을 중시하는 언어라는 것만 짚고 넘어가도록 하겠습니다.
⬆️ 아름다운 도식. 컬러풀한 매력을 가진 언어.
그리고 크고 아름다운 타겟의 수입니다. Kotlin이 가진 강력함은 사실 여기서 출발합니다.
먼저, Kotlin은 Java와 100% 상호 호환됩니다. 거대한 Java 생태계를 흡수할 수 있다는 사실 하나만으로, 이 언어가 가진 무한한 ‘가능성’을 보여줍니다. (이게 가능한 이유는, JVM이나 Android를 타겟으로 했을 때, Kotlin은 일차적으로 자바 바이트코드(.class)로 컴파일되기 때문입니다.)
그 밖에도, Javascript, Native(MacOS, iOS, Windows, Linux, Android NDK를 지원하며, 코틀린 코드를 네이티브 바이너리로 바로 바꿔야 하는 경우 사용), WebAssembly(아직 시험 단계)를 위한 컴파일러를 각각 제공합니다. 단순히 Android Native나 Spring를 이용한 Backend 개발에서 Java라는 언어의 역할을 대체하는 것 이상을 바라보고 있다고 생각하셔도 좋을 것 같습니다. 웹 애플리케이션이나 데이터 사이언스, 임베디드 분야에서도 다른 언어의 지위를 넘보고 싶다는 의도가 다분하니 말이죠. (궁금하신 독자 분들은 Kotlin PlayGround에서 직접 여러 환경을 체험보시는 것도 좋습니다.)
이렇게 공식 답변만 뜯어보더라도 흥미로운 내용이 한 바가지라니! 이어서 Definition으로는 채 다 서술하지 못하는 Kotlin의 특성에 대해 조금 더 알아보고, 이 언어가 과연 궁극적으로 지향하는 바가 어디에 있는지 힌트를 조금만 더 얻어보도록 하겠습니다. 조금 더 힘내어, 걸어 보자구요.
Kotlin의 특성
일단은 재밌어야 한다. 배우는 게 뭐든. Official Site 대문에서 가져온 인상깊은 문구. (Functional의
fun은 아니겠지요..?)
Concise
And Kotlin's mission is to get rid of boilerplate.
Conf'23 당시 Kotlin 프로젝트 리더였던 Roman Elizarov가 컨퍼런스 키노트에서.
비교적 최근에 개발된 언어답게, 문법 자체가 간결한 편입니다. 이러한 면에서 Kotlin과는 대척점에 서 있는, 코드 길이라 하면 둘째가기 서러운 Java와 비교하며 살펴 보겠습니다.
| Java Code | Kotlin Code |
|---|---|
|
|
Kotlin Code 출처: Official Site Code Example, Java Code는 글쓴이가 작성.
두 코드는 정확히 같은 결과를 출력합니다. 그러나 결과를 도출하는 방식에는 많은 차이가 있는데요. 크게 세 가지 부분이 눈에 띕니다.
- Class의 작성을 강요하지 않는다.
- Java System Class에 속한 Method임을 명시적으로 작성하지 않아도 된다.
- Type Inference(타입 추론)를 지원한다. (이는 Java도 지원.)
위의 첫 번째 포인트가 바로 Kotlin과 Java라는 언어의 결을 완전히 다르게 만든 분기점이라고 볼 수 있습니다. Kotlin Community는 객체지향(Object-Oriented)은 물론이고, 함수형 프로그래밍(Functional Programming) 도 “우리 언어가 가진 매력”이라 적극적으로 홍보합니다. 이 부분은 네 번째 특성에서 더 자세히 다뤄볼게요. (Kotiln의 함수는 First-Class Citizen의 조건을 충족합니다. 이는 언어의 간결함을 결정짓는 요소라 볼 수도 있습니다.)
두 번째 포인트입니다. Kotlin은 Standard Library를 통해 기본적인 작업에 필요한 함수들을 구현해 두었습니다. 타겟에 따라, 기존 언어(Java, Javascript)의 메서드를 그대로 가져온 경우도 있고, Native가 타겟인 경우 C++과 Kotlin 자체를 활용해 작성한 것이 보입니다. 꼭 명시해야하나… 싶은 부분을 감췄다는 데에 의의가 있겠네요.
마지막 포인트입니다. 위 Kotlin code에서 name이라는 변수를 선언할 때, 따로 타입을 명시하지 않았습니다. 이는 타입 추론(Type Inference) 를 지원한다는 의미입니다. 굳이 val name: String = "stranger" 이런 식으로 작성하지 않아도 된다는 것입니다.
또 하나의 예시를 볼까요. 이번에는 Class에 대한 이야기입니다.
| *1. Java Class | *2. Kotlin Class |
|---|---|
|
|
Kotlin으로 코드를 작성하면 얻을 수 있는 이점은 Class를 구성할 때 더욱 도드라집니다. 가장 간단하게 Intellij IDEA(또는 Android Studio)에서, *1과 같은 코드를 묶어 ‘Convert Java File to Kotlin File’ 를 클릭하면, *2 와 같은 코드가 됩니다. 줄 수가 무려 반 이상 감소한 모습을 볼 수 있는데요. 정확히 어떤 부분들이 생략되었는지 변환 과정을 톺아보면,
constructor가 Class Header 안으로 들어갔습니다. => 여기 들어간 Constructor를 Primary Constructor라고 합니다. (객체지향을 지원하는 다른 언어들처럼) Class 본문에서 추가로 만들 수 있습니다.constructor에서 사용되는 프로퍼티(Property)는 Class Header의 Parameter로 들어갑니다.- Class Header 안에서 선언된 프로퍼티의 private 필드(field)와 getter/setter 메서드는 명시적으로 표시되지 않고, Kotlin Complier가 자동으로 생성합니다.
기본적으로 Class를 생성할 때 필요한 Boilerplate Code(찍어내듯이 매번 생성해야 하는 코드)가 Kotlin에서는 눈에 띄게 줄어들었습니다. 하지만, 조금 더 나아가, 한 번 더 마법을 써 볼까요?
data class Developer(
val githubUsername: String,
val favoriteLang: String
)
이번에는, 그나마 남아있던 메서드(equals, hashCode)마저 사라졌습니다. class 앞에 data를 붙이면, Kotlin Compiler가 사용자가 작성하지 않은 equals, hashCode, toString, copy. componentN 메서드를 대신 생성해 줍니다.
물론 data class는 일반 Class와 1:1 대응 관계에 있는 것은 아닙니다. 몇 가지 한계가 있는데요, 간단하게만 이야기해 보자면, (Data Classes | Kotlin Documentation 참고)
abstract,sealed,inner,open을 앞에 붙일 수 없습니다.- Primary Constructor는 최소 1개 이상의 프로퍼티를 가져야 합니다.
val또는var로 선언해야 합니다.
위 가정을 충족하지 않는 상황 말고도, data class를 사용하지 말아야 하는 경우가 존재하는데요. (기본적으로 캡슐화(Encapsulation)을 지원하지 않기 때문입니다.) 적절히 사용한다면, 생산성 향상에 이만한 툴도 없습니다. (여담으로, Android Native에서 Model Class 작성 시 매우 편리합니다.)
더 많이, 이 언어의 간결함을 설명하기에, 더 이상의 지면을 할애하기는 글쓴이도 독자도 모두 지치기에 아쉽게 마칩니다만,
아직 배워나갈 건, 써내려 가야 하는 건 더 많으니까요.
takeIf, when, .let 등 흥미로운 구문들은 안드로이드 포스트에서 조금 더 다루도록 하겠습니다.
Safety
반대로 코틀린은 널을 포용한다.
선택성을 표준 라이브러리 대신 타입 시스템의 일부로 넣는다는 말은
코틀린 코드 기반(codebase)가 없음을 뜻하는 값을 일관성 있게 다룰 수 있다는 뜻이다,
(그러나) 코틀린의 널 처리는 완벽하지는 않다.
덩컨 맥그레거, 냇 프라이스, 오현석 역,『자바에서 코틀린으로(Java to Kotlin: A Refactoring Guidebook)』(2021), 한빛미디어, 2022, p.62.
엔터프라이즈(Enterprise)단위의 프로젝트에 있어, Kotlin을 도입하려는 시도에 가장 명확하게 뒷받침되는 요소라 하면 안전성이 될 것입니다. 안전한 프로그래밍 언어란, 개발자로 하여금 오류 가능성을 낮추는 프로그램을 개발할 수 있게 하는 환경을 제공하는 언어입니다. 여기에서는 Kotlin의 안전함을 대표하는 사례 하나를 설명하고자 합니다. 바로 ’Null Safety‘입니다. Null이 어떤 방식으로 타입 시스템의 일부로 포함되었는지 살펴볼게요.
공식 문서를 살펴보면, 이러한 구현의 의도를 명확히 했습니다.
Kotlin's type system is aimed at eliminating the danger of null references, also known as The Billion Dollar Mistake. One of the most common pitfalls in many programming languages, including Java, is that accessing a member of a null reference will result in a null reference exception. In Java this would be the equivalent of aNullPointerException, or an NPE for short.
Kotlin의 타입 시스템은, ‘백만 불짜리 실수’로 흔히 언급되는 널 참조의 위험을 없애는 데 초점을 맞추어 개발되었습니다. Java를 포함해, 수많은 프로그래밍 언어가 가진 함정은, 널 참조의 멤버에 접근하는 시도 자체가 “null reference exception”으로 이어진다는 것입니다. 이를 Java에서는NullPointerException으로 취급하며, 짧게 NPE라고 부르기도 합니다.
“그래서 우리는 Null을 타입으로 만들기로 했어요.”
가 핵심 논지입니다. 정확히는 Kotlin Type System이 참조(Reference)의 방식을 크게 두 가지로 분류한 것입니다. null을 포함할 수 있는 참조(nullable reference)과 그렇지 않은 참조(non-nullable reference)가 그것입니다. 간단한 예시를 살펴 보죠.
| Non-nullable | Nullable |
|---|---|
|
|
|
|
위 코드에서, (Generic를 아는 독자라면 익숙한 알파벳) T? 는 T 를 포함한다는 것을 쉽게 알아챌 수 있습니다. 뒤에 ?을 붙임으로써, 기존 타입이 null을 포함할 수 있음을 표현한 것이죠. (즉, null이 다른 원시 타입들처럼 메서드를 가지거나 독립적으로 그것의 Instance를 생성할 수 없다는 이야기입니다. 그럴 이유도 없고 말이죠.) null이 기존 타입 시스템에 편입됨으로써 가지는 가장 큰 이점은 Runtime Error를 크게 줄여준다는 것입니다. (어느 정도 규모를 가진) Codebase를 (Java에서 이야기하는) NPE 없이 유지하기는 매우 어려운 일이기 때문에, 이는 생산성 향상과 소프트웨어의 안정성에 큰 도움을 줄 수 있습니다.
하지만 Kotlin의 Null-Safety가 완전한 것은 아닙니다.
다시 말해서, Kotlin에서 ‘없음’을 표현하는 것이 항상 null이라는 건 아니란 이야기입니다. 몇 가지 예시를 들어보죠.
| Code | Result |
|---|---|
|
|
|
|
|
|
Map<K,V>.get(key)는 key에 해당하는 값이 없을 때 null을 반환하지만, List<T>.get(index)는 index에 해당하는 값이 없을 때 ArrayIndexOutOfBoundsException을 던지고, 이와 비슷하게 Iterable<T>.first()는 NoSuchElementException을 던집니다.
결국 이는 Java와의 호환성을 유지하려고 생긴 문제인데요. 하지만 null을 타입 시스템 안으로 끌어안을 때 생기는 이점이 압도적으로 많기에, 이러한 예외들은 기꺼이 감수해야 하지 않을까.. 싶기는 합니다. 하지만 앞으로 Kotlin 생태계에서 논의해볼 문제이기는 합니다. 일관성 있는 예외 처리는 독립된 언어의 정체성을 구성하는 데 중요한 요소이기 때문입니다.
Asynchronous
비동기 처리는 어떤 (웹이던 앱이던) 애플리케이션을 제작하든 간에 핵심적인 로직을 차지합니다. 동시 실행(Concurrency)에 대한 강력한 지원, Kotlin은 (뒤에서 다룰) 방대한 야망의 일각을 1.3 release에서부터 Coroutine으로 드러내기 시작했습니다.
언제나 그랬듯이, 공식 문서로부터 우리의 이야기는 출발합니다.
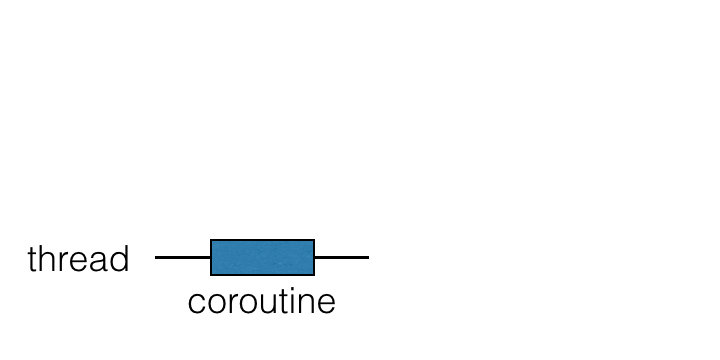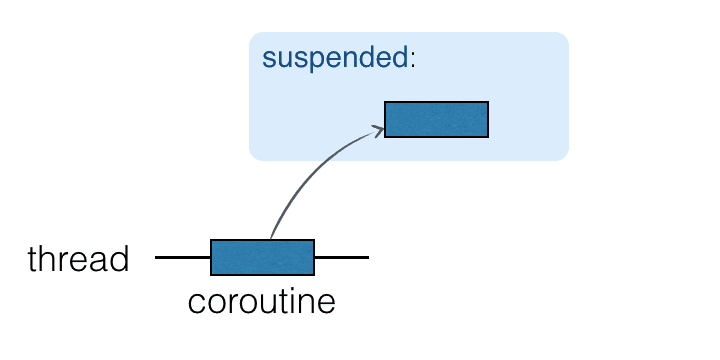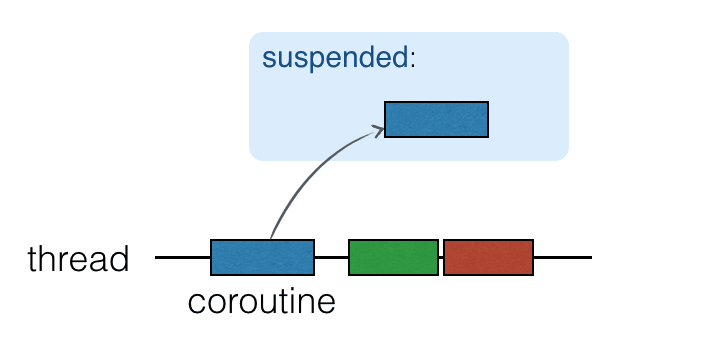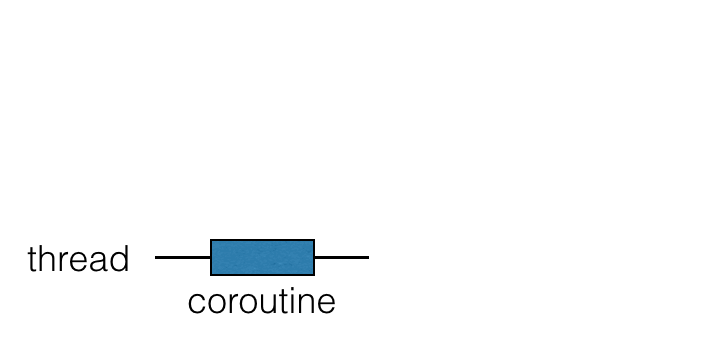
A coroutine is an instance of a suspendable computation. It is conceptually similar to a thread, in the sense that it takes a block of code to run that works concurrently with the rest of the code. However, a coroutine is not bound to any particular thread. It may suspend its execution in one thread and resume in another one.
코루틴은 Suspendable Computation 의 인스턴스입니다. 일정한 블록의 코드를 가져다, 나머지 코드와 병렬적으로 실행토록 한다는 컨셉 자체는 스레드와 유사합니다. 하지만 코루틴은 어떠한 특정 스레드에도 (1:1로 대응되어) 바인딩되지 않습니다. 이는 (특정 코루틴이) 하나의 스레드에서 실행을 잠시 멈추었다가, 다른 스레드에서 재개될 수도 있다는 것입니다.
첫 번째 질문. 여기서 Suspendable Computation이라는 게 무엇을 의미하나요?
말 그대로 중단(suspend) 그리고 재개(resume)가 가능한 Computation (이 맥락에서 ‘계산’으로 직역하기 어려운 까닭에 앞으로도 그대로 옮겨 적겠습니다)을 의미합니다. 그리고 Suspendable Computation은 Kotlin에서 suspend fun으로 구현됩니다. 그렇다면 공식 문서에서 코루틴을 suspend fun의 인스턴스로 언급하는 이유는 뭘까요? 이는 코루틴을 생성하는 함수인 CoroutineScope.launch를 깊게 들여다보면 조금이나마 힌트를 얻을 수 있습니다.

kotlinx-coroutines-core/common/src/Builders.common.ktpublic fun CoroutineScope.launch( context: CoroutineContext = EmptyCoroutineContext, start: CoroutineStart = CoroutineStart.DEFAULT, block: suspend CoroutineScope.() -> Unit ): Job { val newContext = newCoroutineContext(context) val coroutine = if (start.isLazy) LazyStandaloneCoroutine(newContext, block) else StandaloneCoroutine(newContext, active = true) coroutine.start(start, coroutine, block) return coroutine }
CoroutineScope.launch의 파라미터 중 block은 주어진 CoroutineScope에서 실행될 Coroutine Code를 의미합니다. 즉, launch()는 suspend fun인 코드의 block 으로부터 Coroutine을 생성하는 함수라는 것입니다.
그러니 ‘코루틴이 Suspendable Computation의 인스턴스이다’를 다르게 말하면, Class가 인스턴스를 찍어내듯 Supendable function은 Coroutine을 (launch()나 async()와 같은 Coroutine Builder를 통해) 생성한다는 이야기입니다.
두 번째 질문. Suspendable function은 정확히 코루틴에서 어떤 역할을 하고 있나요?
When the computation is ready to be continued, it is returned to a thread (not necessarily the same one).
Computation이 동작을 재개할 준비를 마치면, 스레드로 복귀합니다. (복귀하기 전 스레드와 같은 필요는 없습니다.)
이미지 및 텍스트 출처: Kotlin Docs: Coroutines and channels - tutorial
위 그림은 코루틴이 스레드 위에서 주로 어떤 동작을 수행하는지 알기 쉽게 알려주는 도식입니다. 사실은 혼란을 가중시킬 수 있는 그림이기도 한데요. 정의(Definition)를 저 멀리 눈에 보이지 않는 곳에 두고, 도형이 움직이는 것만 보자 하면 “코루틴이 suspendable한 function을 생성하는 것인가?”라고 오해할 가능성도 다분하기 때문입니다. (사실은 그 반대라는 건 앞에서 언급했습니다.) 정확히는 “코루틴 안에서만 suspendable한 function을 실행할 수 있는 것” 입니다. (그리고 suspend fun 안에서 다른 suspend fun을 실행할 수 있습니다. 전자나 후자 모두 코루틴 안에서 실행되는 것이기 때문입니다.) 즉 이는, 일반적인 function에 코루틴의 실행을 정지하는 역할이 부여되었다고 보아도 무방합니다.
세 번째 질문. 그렇다면 (스레드와는 다르게) 코루틴은 어떻게 생성되고 관리되나요?
이 단락은 [Suhwan Jee: Kotlin Coroutine의 Structured Concurrency 구현 상세]에게 많은 빚을 지고 있습니다. 언급되는 코드와 도식은 위 포스트의 자료를 편집한 것임을 밝힙니다.
기본적으로 코루틴은 CoroutineScope 안에서만 생성될 수 있습니다. 이를 멋지게 표현하면, Scoped Execution을 지원한다고 하는데요. CoroutineScope는 (Scope 안에서 생성된) 코루틴을 언제 시작할지, 멈출지, 재개할지 결정합니다. (즉 launch()나 async()와 같은 Builder를 CoroutineScope 안에서만 쓸 수 있다는 것입니다.) 굳이 Scope 안에서의 사용을 강제하는 이유에는 크게 두 가지가 있습니다.
- 코루틴의 Grouping을 가능하게 합니다.
=> 이는 Scope가 Cancel되면, Scope 안에서 시작되었던 코루틴은 모두 Cancel된다는 것입니다. => 특정 코루틴이 더 이상 불필요한 경우, 이는 리소스의 낭비를 막는 효과를 낳습니다.
- Coroutine Scope는 코루틴이 실행되는 Context를 정의하는 데 도움을 줍니다.
위와 같은 사실은 코루틴의 구현이 Structured Concurrency(구조적 병렬성) 의 원칙을 충실하게 따랐기 때문입니다. 사실 처음에 언급했던 “Kotlin이 동시 실행에 강력함을 지닌다” 라는 이야기는 (세 번의 질문을 돌고 돌아) 여기에서 그 근거를 찾을 수 있게 된 것입니다. 간단한 도식과 함께 코드를 살펴볼까요.
fun doConcurrentJob
= coroutineScope { /* coroutine 1 */
launch { /* coroutine 2 */
launch { /* coroutine 3 */
launch { /* coroutine 4 */
}
}
launch { /* coroutine 5 */
}
}
}
⬇️ 위 코드를 도식화.
Structured Concurrency 를 지원하기 위해, 코루틴은 트리 구조의 형태로 작성되어 있습니다. 즉, 부모-자식(parent-child) 관계를 지니고 있다는 의미입니다. 위에서는 Grouping이라는 개념으로 뭉뚱그려 설명했지만, 정확히는 트리 형태를 갖추고 있다고 이야기하는 것이 맞습니다. 또한 Context를 정의하는 데 도움이 된다는 것도, 결국 자식 코루틴이 자신의 Context를 정의하는 데 부모 코루틴의 Context를 가져오기 때문입니다. (간단하게, myContext = this + parentContext, 이런 식으로 말이지요.) 이와 같은 구현은 다음과 같은 것들을 가능하게 합니다.
- Structured concurrency ensures that they are not lost and do not leak. An outer scope cannot complete until all its children coroutines complete.
구조적 병렬성은 코루틴이 누수되거나 손실되지 않을 것임을 보장합니다. 외부 Scope는 모든 자식 Scope의 작업이 끝날 때까지 (생명 주기를) 완결하지 않습니다.
- Structured concurrency also ensures that any errors in the code are properly reported and are never lost.
또한 코드 상의 모든 에러가 누락 없이 정확하게 보고될 것임을 보장합니다.
코루틴을 사용해 코드를 작성하는 관점에서, 위의 이야기를 풀어서 이야기하면, (1.) 부모 Coroutine이 어떤 이유로든 취소되면, 모든 자식 Coroutine은 취소됩니다. 또한, (2.) (명시적으로 취소를 하지 않는 한) 자식 Coroutine이 Exception을 던지면, 부모 Coroutine으로 Exception이 전달되어 parent를 취소시킵니다.
이는 일반적인 (즉 Structured가 아닌) 동시성 프로그래밍이 가지는 수많은 난점을 해결합니다. (C와 C++을 제외한 고수준 언어에서는 거의 사용되지 않는) goto와 크게 다르지 않게, 코드의 가독성(그리고 구조적 프로그래밍)을 해치던 예약어들, (예를 들어 callback, promise, future 등등..)의 구속에서 드디어 해방될 수 있는 것입니다. 코루틴을 사용하면, 큰 힘 들이지 않고, 동시에 실행되는 로직에 대해 명확한 역할과 한계를 부여할 수 있고, 오류에 대한 명확한 Report를 받아볼 수 있습니다.
Object-oriented or Functional
객체 지향 프로그래밍은 메시지를 객체에 보내서 문제를 해결하는 기술이다.
myString의 길이를 알고 싶은가? 그 객체에myString.length()라고 메시지를 보내라. 콘솔에 문자열을 출력하고 싶은가? 문자열을 메시지에 넣고 콘솔을 표현하는 객체에System.out.println(myString)처럼 출력을 요청하라. 고전적인 객체 지향 언어에서는 클래스에 메서드를 정의해서 객체가 메시지에 반응하는 방법을 정의한다.(중략)
반대로 함수형 프로그래밍에서는 값을 사용해 함수를 호출함으로써 문제를 해결한다.
myString의 길이를 알고 싶으면length(myString)처럼 함수에 값을 넘긴다. 콘솔에 문자열을 출력할 때는println(myString)을 호출하고, 다른 장치에 문자열을 출력하고 싶다면println(myString, System.err)같이 원하는 장치를 함수에 전달해야 한다. 함수는 타입 위에 정의되지 않고, 함수의 파라미터와 결과가 타입을 소유한다.
덩컨 맥그레거, 냇 프라이스, 오현석 역,『자바에서 코틀린으로(Java to Kotlin: A Refactoring Guidebook)』(2021), 한빛미디어, 2022, pp.177-178.
(고전적인 객체 지향 언어 에 가까운) Java와의 100% 상호 운용성을 지원하는 만큼, Kotlin으로 객체 지향 코드를 작성하는 것은 언어의 결을 거스르지 않는 일입니다. 심지어 Kotlin으로 마이그레이션 했을 때 ( Kotlin의 특성: Concise에서도 언급했듯이, ) 클래스 작성 시의 Boilerplate가 크게 줄어드는 마법도 우리는 목격했습니다. 그렇다면 신나게 OOP로만, Kotlin 코드를 작성하면 될 일일까요? 표현이 거칠었지만, 이는 언어가 가진 매력을 (조금은) 퇴색시키는 일입니다. Kotlin은 멀티 패러다임(Multi-Paradigm) 언어니까요.
(어쩔 수 없이 이 글에서 많이 등장하는 언어인) Java에서의 모든 코드는 클래스(Class)의 필드(field)와 메서드(method) 로 치환됩니다. (정확히는 JVM을 사용하는 모든 언어, 당연히 JVM을 타겟으로 하는 Kotlin도 바이트코드로 컴파일되면 그러합니다.) 그러니 Java라는 무기를 가진 상황에서 컴퓨팅적 문제에 맞딱드린 경우, 개발자들은 보통 클래스에 메서드를 정의하여 해결하는 객체지향적 접근법을 취하는 경우가 많습니다.
(하지만 Java로 함수적 접근을 할 수 없다는 것은 아닙니다. 옛날 옛적 순수한 Java 1.0에서의 함수는 일급 객체의 조건을 충족하지 못했지만, JDK 8(1.8)부터 본격적으로 Stream API를 지원하며 멀티 패러다임에 한 발짝 더 다가섰습니다.)
Kotlin의 경우, 개발 초기부터 멀티 패러다임을 지원하기 위해 노력한 흔적들이 보입니다.
두 언어 모두에 존재하는 println()이 어떻게 개발자의 냉장고에 발을 들이게 되었는지 비교하며 살펴볼까요?
먼저 Java입니다.
System.out.println("Hello, Readers!");
슬쩍 보자하니 (기본으로 import되어 있는) java.lang 패키지에 포함된 System Class에서 무언가를 가져오는 것 같습니다.
네 맞습니다, out이라는 static 필드를 가져옵니다. (static 필드이므로 우리에게는 System Class의 인스턴스가 필요하지 않죠.) 그렇다면 우리는 out이 어떤 형태를 가진 property인지 또 찾아나서야 합니다.
public final static PrintStream out = null;
그렇습니다, out은 PrintStream의 인스턴스였던 것입니다. 그렇다면 분명 Java의 println()은 PrintStream이라는 클래스의 메서드일 것입니다. (예상이 아니라 이는 사실입니다. 같이 공부하려는 방식을 취하다 보니 표현이 조금 어색해졌네요.) 결론적으로 Java의 println()은 객체가 메시지에 반응하는 방법을 정의한 하나의 ’메서드‘입니다.
그런데 Kotlin의 println()은 조금 다른 방식으로 정의되어 있습니다. (일부러) Java와의 접점을 없애기 위해, Native가 타겟인 경우의 Console Source를 가져와 보았습니다. 함께 보시죠.
kotlin-native/runtime/src/main/kotlin/kotlin/io/Console.kt/* * Copyright 2010-2018 JetBrains s.r.o. Use of this source code is governed by the Apache 2.0 license * that can be found in the LICENSE file. */ package kotlin.io import kotlin.native.internal.GCUnsafeCall /** 중략 */ /** Prints the given [message] and the line separator to the standard output stream. */ @GCUnsafeCall("Kotlin_io_Console_println") @PublishedApi internal external fun println(message: String) /** Prints the given [message] and the line separator to the standard output stream. */ public actual fun println(message: Any?) { println(message.toString()) } /** Prints the line separator to the standard output stream. */ @GCUnsafeCall("Kotlin_io_Console_println0") public actual external fun println() /** 후략 */
가독성을 위해 파일에 존재하는 대부분의 코드를 가렸지만, 전달하려는 바는 그보다 더 간결합니다. Kotlin의 println()은 Class 안에 존재하지 않는다는 사실입니다.
(JVM이 타겟인 경우에는, 어떻게 보면 당연하게도, 함수 안에서 System.out.println()을 호출합니다.
네이티브의 경우, 다음과 같은 C++ Source를 통해 원하는 메시지를 콘솔에 출력합니다. 후자는 객체지향의 특성이 아무리 눈을 크게 뜨고 보아도 전무하다시피 합니다.)
Kotlin은 println()과 같은 경우처럼, 함수(그리고 프로퍼티와 상수)를 Class 밖에 선언할 수 있도록 허용합니다. 이를 지적인 말로, ’최상위 함수(Top-level Function)‘를 선언할 수 있다고 이야기합니다. 사실상, Java에서 기존 Class에 함수를 추가하기 어렵거나 불가한 경우 사용하는, static 메서드를 대체한다고 보아도 무방합니다. 하지만 어떻게든 클래스에 묶이게 되는 Java의 메서드와는 달리, 최상위 함수의 경우 인스턴스 영역에 있지 않으므로, 선언하고 이를 참조하는 것이 더욱 간단합니다.
또한 Kotlin은 함수를 First-Class Citizen(일급 시민)으로 취급합니다. 이는 생태계 안의 고차 함수(Higher-Order Function)와 중첩 함수(Nested Function)의 존재를 저절로 일깨워줍니다.
Kotlin functions are first-class, which means they can be stored in variables and data structures, and can be passed as arguments to and returned from other higher-order functions. You can perform any operations on functions that are possible for other non-function values.
Kotlin 함수는 일급 객체입니다. 이는 (함수가) 변수에 할당하거나 자료구조에 저장될 수 있으며, (함수나 객체의) 인자로 전달되거나, 다른 고차 함수의 리턴값이 될 수 있다는 뜻입니다. 함수가 아닌 값들을 가지고 했던 어떤 작업이든 (함수를 핸들링하며) 가능합니다.
이를 용이하게 처리하기 위해, 정적 타입 프로그래밍 언어인 Kotlin은, 함수를 표현하기 위해 함수 타입을 사용하고, 람다 표현식과 같은 특수한 구조를 제공합니다.To facilitate this, Kotlin, as a statically typed programming language, uses a family of function types to represent functions, and provides a set of specialized language constructs, such as lambda expressions.
출처: Higher-Order functions and lambdas | Kotlin Documentation
Higher-Order Function, Lambda Expression, Extension Function에 대해서는 (특히 안드로이드 관련한) 다른 포스트에서 조금 더 깊게 다루어 보도록 하겠습니다. 이 글에서는 이만 줄여볼게요.
개행이 포함하여 출력하는 함수, println(). 프로그래밍 언어에서 가장 단순하다고 생각되는 함수 하나를 가지고, 선택할 수 있는 가장 먼 길을 돌아온 것은, Kotlin 생태계가 가진 일종의 결을 따라가기 위함이었습니다. 그리고 우리는 여정의 끝에 거의 다다랐습니다. 이 언어가 가진, Kotlin이라는 개발 커뮤니티 안의 사람들이 공동으로 추구하는 지향점, 그 어딘가에 존재하는 섬을 향해, 과연 우리는 어느 방향으로 뱃머리를 돌려야 할까요? 여러분은 감이 오셨나요?
Kotlin의 지향점
안정성 그리고 다양성. Stability and Diversity.
긴 항해 끝에 이 글이 다다른 결론입니다. Kotlin은 위의 두 가치를 기반으로 두고 개발되었고, 지금도 그러하다는 것을요.
여기에 '간결함'이라는 친구가 왜 이름을 올리지 못했냐며 의아해할 독자 분들을 위해 짤막하게(?) 설명을 덧붙이려 합니다. 정확히 이야기하자면 이 분은 자리를 빼앗긴 것이 아닙니다. 그는 안정성의 일부로 그의 몫을 다하고 있지요. 코드의 간결함은 흔히 생산성과 직결되기 쉬운데, '코드를 더욱 빠르게 작성할 수 있다'라는 사실과는 더욱 밀접합니다. (이를 프로그래밍 언어론Programming Langauge Theory 에서는 'Writablilty'라고 합니다.) 하지만 우리는 다른 측면의 '생산성'에 눈을 돌릴 필요가 있습니다. 많은 개발자분들이 공감하시겠지만, 코드는 처음 작성하는 시간보다 이를 고치는 데 (과장을 힘껏 보태서) 억겁 배의 시간이 소요된다는 것을요. 간결한 코드는 이 수많은 순간들에서 빛을 발합니다. 그 이유는 간단합니다. 우리에게 필연적인 실수들을 '코드를 되짚는 지금'에 이르러서라도 발견하게끔 하기 때문이죠. 이를 언어가 가진 '디버깅 안정성 Stability for Debugging'이라 부를 수 있겠네요. (엄밀하게는 'Readability'라고 합니다.) 이 글에서는 주로 Kotlin의 Codebase가 가진 안정성에 대해서만 이야기했지만, 프로그래밍 언어의 안정성에는, 이러한 측면도 포함되어야 한다고 생각합니다. (즉, 하나의 프로그래밍 언어가 '간결하다'라고 이야기하려면 Writability와 Readability에서 모두 높은 평가를 받아야 한다는 것입니다. ) 이런 부분들은 추후 Android 포스트에서 글쓴이가 직접 작성한 코드를 하나씩 뜯어보며 그 중요성을 더 음미해보도록 하겠습니다. 조금의 시간을 두고 여유롭게 말이죠.
안정성 Stability
프로그래밍 언어의 안정성은, 이론적으로는, Reliability(신뢰성 또는 신뢰 가능성)으로 치환되어 언급됩니다. (이 글에서는 Kotlin의 간결함과 더불어 Codebase의 안정성을, 영어로는 Stability로 통일하여 언급했습니다. 즉, 위의 텍스트에서는 프로그래밍 언어론의 엄밀한 이론적 체계를 따르지 않았음을 밝혀 둡니다.)
앞에서 언급한 특성들 중, Null-Safety(널 안전성)와 Structured Concurrency(구조적 병렬성)가 Kotlin의 안정성(여기서는 Reliability)을 지탱합니다. 그 이유를, ChatGPT가 작성해준 프로그래밍 언어의 신뢰성에 “기여하는” 요소를 한 조각씩 분해하며 찾아 보도록 하겠습니다.
Key factors that contribute to the reliability of a programming language include: 프로그래밍 언어의 “신뢰성” 을 높이는 요소들은 다음과 같습니다:
-
Type System: The type system of a programming language determines how it handles data types and type checking. Strong, statically typed languages can catch many errors at compile time, leading to more reliable code. => 타입 시스템: 프로그래밍 언어의 타입 시스템은 데이터 타입을 어떻게 구성하고, 이에 대한 점검을 어떻게 수행할 것인지 결정합니다. 강 타입, 정적 타입 언어들은 컴파일 시에 많은 오류를 잡아낼 수 있으므로, (약 타입, 동적 타입의 지원하는 언어들에 비해) 더 '신뢰 가능한' 코드를 작성하는 데 유리합니다.
-
Error Handling
-
Memory Management
-
Concurrency Support: In multi-threaded or concurrent applications, the language's support for managing threads and synchronizing access to shared resources affects reliability. Languages with built-in support for concurrency and synchronization mechanisms can help developers avoid race conditions and other issues. => 병렬성 지원: 멀티 스레드를 사용하거나 병렬적인 기능을 지원하는 애플리케이션의 경우, 언어 차원의 지원은 "신뢰성"에 큰 영향을 끼칩니다. 병렬성과 동기화 메커니즘을 내재한 언어는 (개발자들이) Race Condition 등의 이슈를 피하는 데 도움을 줍니다.
-
Standard Library
-
Tooling and Ecosystem
-
Testing and Debugging Support
-
Documentation
-
Long-Term Support
-
Community and Code Reviews
Null Safety는 Kotlin의 타입 시스템을 단단하게 만들어주는 요소 중 하나입니다. 앞에서 인용한 대로, Kotlin의 설계자들은 ”선택성을 표준 라이브러리 대신 타입 시스템의 일부로 넣음 “으로써 없음에 대한 처리에 일관성을 부여했습니다. 일반적으로, 다른 언어에서 타입 시스템에 대해 이야기한다면, ‘강’이냐 ‘약’이냐(Strong-Typed or Weak-Typed), ‘정적’이냐 ‘동적’이냐(Statically-Typed or Dynamically-Typed) 에 초점을 맞춥니다. 그리고 두 조건 모두에서 전자를 충족해야 더 ‘안정적’이라 이야기합니다. (물론 Kotlin은 Strongly-Typed이자 Statically-Typed Language입니다.)
여기서 Kotlin 생태계는 한 걸음 더 나아가, 모든 타입을 (정확히는 참조(Reference)의 방식을) 이원화함으로써, 컴파일 타임의 오류를 ‘잡아내는’ 것에 그치지 않고, ‘없애는’ 데에도 기여하였습니다. 타입 시스템에 있어, 어떤 프로그래밍 언어의 ‘신뢰 수준이 높다’ 라는 건, Built-In으로 실수와 사고의 가능성을 줄이는, 자동차의 주행 보조 장치와 같은 것을 지니고 있다는 뜻이기에, 널 안정성은 그러한 의미에서 (Type System을 떠받치는) 기둥이 될 자격이 충분합니다.
또한 Structured Concurrency의 원칙에 따라 구현된 코루틴이라는 라이브러리는, Kotlin이 ‘동시 실행’에 있어 얼마나 강력한 역량을 가진 언어인지 실감케 합니다. 단순히 멀티 스레딩(Multi-Threading)과 비동기(asynchronous) 프로그래밍을 언어 차원에서 지원할 뿐 아니라, 코루틴은 이에 ‘구조화된’ 안정성을 보탰습니다. 이게 가능했던 이유는, ‘누수 없는’ 동시성 프로그래밍을 지향하는 개발자들이, 코루틴에 (아쉽게도 앞에서 언급하지 않았지만) Python trio 라이브러리의 nursery 블록의 개념을 도입했기 때문입니다.
이제 앞에서 언급한 내용들을 정리하면,여기서 Nursery가 무엇인가요? [1]
다익스트라는 그의 논문[2]에서 이렇게 언급합니다.Nurseries: a structured replacement for go statements
Here's the core idea:
every time our control splits into multiple concurrent paths, we want to make sure that they join up again.
So for example, if we want to do three things at the same time, our control flow should look something like this:
핵심 아이디어:
프로그램의 흐름이 병렬적으로 나뉠 때마다, 우리는 (이 흐름이) 다시 합쳐지기를 바랍니다.
세 가지 작업을 동시에 처리하고 싶을 때, Control Flow는 다음과 같아야 합니다.
⬆️ 위 Flow는 레퍼런스[1]의 도식을 코루틴으로 치환하여 글쓴이가 재구성한 것입니다.
Notice that this has just one arrow going in the top and one coming out the bottom, so it follows Dijkstra's black box rule.
상단에 존재하는 하나의 화살표가 하단에서 하나의 화살표로 끝맺어 집니다. 이는 다익스트라(Edsger W. Dijkstra)의 Black Box Rule을 충족합니다.There is also an abstraction involved in naming an operation and using it on account of "what it does" while completely disregarding "how it works".
특정 동작에 이름을 붙이며, 그 동작이 어떻게 작동하는지 완전히 무시한 뒤 그것이 무엇을 하는지에만 포커스를 맞추는 것, 추상화는 바로 그 지점에도 존재합니다.
다익스트라는 개발자들이 "자신의 지적 능력으로는 한 번에 이해하기 어려운that are too big to hold in your head all at once " 코드를 작성할 수 있으려면, 구조적 프로그래밍(Structured Programming)이 필요하다고 역설했습니다. 이 논문이 쓰여질 당시만 해도 프로그래밍의 세계에서는goto가 횡행했으니까요. 그러면 인용한 부분의 'abstraction'과 구조적 프로그래밍은 어떤 관련이 있는 걸까요? (누구보다 장황하지만 구조적인 글을 지향하는 글쓴이는 지양하는 방식이지만) 간추려 이야기해 보겠습니다. 단순한 함수 하나를 보시죠.
println("Hello World!")
보통 Kotlin에서println()을 사용할 때, (이 글에서 다루었던 것처럼) 콘솔 소스를 뒤져보거나 하지 않습니다. (그러한 행위는 온전히 순수한, 학문적 호기심의 발로이므로 자주 시도하지 않으시는 걸 추천드립니다.) "어떻게 동작하는지는 뒤로 제쳐두고," 그저 "그 동작을 사용"할 뿐입니다. 여기서 동작operation이란 함수(Function), 조건문/반복문 안의 코드, 클래스의 메서드(method) 등을 모두 포괄하는 말입니다.
즉, 우리는 프로그램을 구성하는 진정 모든 요소를 이해할 필요가 없습니다. (다익스트라는 이를 코드에 'Black Box'를 적절히 씌우는 행위라고 이야기합니다.) 적절한 추상화를 통해, 동작의 결과와 방향성을 이해하기만 하면 될 뿐입니다. 이는 우리가 사용하는 모든 동작의 결말이, 수많이 존재하는 강의 지류가 결국 바다로 비롯되는 것처럼, 하나의 흐름으로 모일 것임을 믿기 때문에 가능한 일입니다. 대부분의 현대 프로그래밍 언어는goto를 지양함으로써 위와 같은 구조적 프로그래밍의 원칙을, 최소한 표면적으로는, 준수합니다.
nursery는 동시성 프로그래밍에, 이러한 구조적 프로그래밍의 특성을 적극적으로 도입하려는 Python 생태계의 놀라운 발명품이라고 할 수 있겠습니다. (정확히는 이 텍스트를 구성하는 데 지대한 공헌을 한 블로그의 주인장, Nathaniel J. Smith의 작품입니다.) 핵심은 (코루틴과 비슷하게)nursery블록 안에서 시작된 동시성 흐름은 반드시 그 안에서 종료되며, 한 지점에서 끝맺어짐을 보장하는 것입니다.
⬆️ Coroutine은 Standard Library라는 기둥을 받치고 있는 것이 (엄밀하게는) 맞으나, 편의상 위와 같이 제작하였음을 밝힙니다.

이런 그림이 나올 수 있겠네요. 그럼으로써 우리는 코틀린의 ‘안정성’에 대한 탐험을 미약하게나마 마쳤습니다. 이제 다른 섬으로 모험을 떠나볼까요?
다양성 Diversity

사진 한 장으로 요약 가능. ⬆️ 출처: Kotlin Overview: Kotlin Multiplatform
사실 글의 첫머리에서 Kotlin의 정의를 살펴볼 때, 모든 힌트는 주어졌습니다. 앞서 글쓴이는 해당 텍스트를 톺아보며 ‘정적 타입Statically-Typed‘과 ‘타겟Target‘에 주안점을 두고 논지를 전개해 나갔는데요. 그렇게 하고선 Kotlin의 네 가지 특성을 살펴본 뒤, 다시 이 언어가 지향하는 두 지점을 향해 항해했습니다. 그리고 그 두 지점은 우리 여정의 시작과 맞닿아 있습니다. 결국 이 단락도 그러한 회귀의 일부입니다.
‘안정성’과 마찬가지로, Kotlin의 ‘다양성’도 단순히 한 가지 개념만을 담고 있는 것은 아닙니다. 크게 네 차원에서의 다양성을 이야기해볼 수 있는데요. Usage, Target, Platform, Code Style이 바로 그것입니다. Code Style를 제외한 셋은 밀접히 관련되어 있지만, 사용되는 맥락이 조금씩 다릅니다. (그리고 네 번째 차원에 대한 이야기는 Object-Oriented or Functional에서 다루었으니 여기서는 생략하겠습니다.)
Usage: 무엇을 개발하는 데 Kotlin을 사용할 것인가
쉽게 말해 “Kotlin으로 뭐 만들 수 있어?” 입니다. 공식 홈페이지의 내용(Kotlin이 제공하는 Solution)을 토대로 정리해 보면 다음과 같습니다.
- Android Native
- Server-Side
- Multiplatform Application
- Client-Side Web Application
- Data Science
강조한 부분을 제외한 세 가지 분야는, Java와의 100% 상호 운용성이 바탕에 있습니다. 안드로이드 네이티브 개발이나 Spring을 이용한 백엔드 개발은 원래 Java로 이루어진 것이었고, Jupyter나 Zeppelin을 이용한 Data Science에 대한 지원도, 기존에 존재하던 JVM 기반의 라이브러리를 바탕으로 출발한 것입니다. (Kotlin 전용으로 개발된 백엔드 프레임워크 Ktor에 대해서는 다른 포스트에서 다뤄보겠습니다.)
하지만 나머지 두 분야는 조금 다릅니다. JVM과는 무관하게, 오롯이 Kotlin 생태계에서 창발된 것들입니다. (모바일 뿐 아니라 데스크톱이나 웹을 포함하여) 다양한 플랫폼에서 동작하는 애플리케이션을 하나의 언어로 작성한다거나, 웹사이트를 JavaScript가 아닌 언어로 개발한다는 것, 그리고 전자와 후자의 ‘언어’가 같은 생태계를 지칭한다는 건, 조금 어색한 이야기로까지 들립니다.
위와 같은 일들을 가능하게 하려면 여러 요소들이 뒷받침되어야겠지만, 가장 중요한 것은 Kotlin으로 작성된 코드를 상황에 따라 ‘어떻게 변환시키냐’에 달려 있습니다. 그래서 우리는 Target에 대한 이야기로 발걸음을 옮길 수 밖에 없습니다. 다음 스텝을 밟아 볼까요?
Target: Kotlin을 어떻게 컴파일할 것인가
Kotlin 컴파일러는 크게 네 가지 타겟(Target)을 가집니다. JVM(Java Virtual Machine), JavaScript, WebAssembly, 그리고 Native가 그것입니다.
JVM을 타겟으로 하는 경우, 우리가 작성한 Kotlin 코드는 Java 8 바이트코드(.class)로 컴파일[3]됩니다. 이후에는 온전히 JVM의 손에 맡겨집니다. 이를 통해 Java 생태계의 가장 큰 장점인 ‘운영체제에 대한 독립성’을 저절로 확보하게 됩니다. (이를 흔히 Write Once, Run Anywhere: WORA 원칙이라고 하죠.) 대부분의 Kotlin 코드는 JVM의 손을 거쳐 0과 1이 됩니다.
타겟이 JavaScript인 경우, ES5.1 버전의 코드로 변환되며, 이는 CommonJS와 AMD(Asynchronous Module Definition) 모듈 시스템과의 호환을 지원합니다.[4] 또한 (아직 실험 단계이기는 하지만,) WebAssembly로의 컴파일도 가능합니다. 컴파일러가 이 두 타겟을 지원함으로써, 클라이언트 사이드의 웹 개발이 가능해지며, 명시적으로 Java와의 첫 번째 분기(分岐)가 일어납니다.
Why Kotlin Native?
Kotlin/Native is primarily designed to allow compilation for platforms on which virtual machines are not desirable or possible, such as embedded devices or iOS. It is ideal for situations when a developer needs to produce a self-contained program that does not require an additional runtime or virtual machine.
Kotlin/Native는 Virtual Machine의 구동이 불가능하거나 적절하지 않은 플랫폼 - 임베디드나 iOS 디바이스 - 위에서 Kotlin 코드를 컴파일할 수 있도록 처음 디자인되었습니다. 추가적인 런타임이나 Virtual Machine이 필요하지 않은 Self-Contained 프로그램을 개발하려 할 때, 이상적인 선택지입니다.
Native의 경우, 이름이 말해주듯, Kotlin 코드는 Virtual Machine을 거치지 않고 Binary로 컴파일됩니다. 모든 경우에서 JVM이 만병통치약이 아니기 때문에, (특히 임베디드나 macOS, iOS에서 Desirable한 해결책이 아니기 때문에,) 궁극적인 Multiplatform 지향성을 갖추기 위해서 (그리고 속도를 위해서,) Kotlin의 개발자들은 Native Complier가 필요하다고 판단한 것 같습니다. 두 번째 분기는 여기서 일어납니다. Java와는 달리 ‘운영체제 독립성’과 ‘의존성’을 모두 취한 것이죠.
컴파일 가능성에 대해 알아보았으니, 우리는 Kotlin으로 작성한 애플리케이션을, 다양한 환경에서, 어떻게 동작(Run)시킬 수 있을지 고민해야 합니다.
Platform: 어떤 환경에서 Kotlin Software를 사용할 것인가

⬆️ 출처: Kotlin Overview: Kotlin Multiplatform
Write Single Logic, Use it for Any Platform. 공통 로직을 작성하고, 어떤 플랫폼을 위해서든 동작하게 하자.
얼핏 보면, 위 문장은 다른 Cross-Platform 프레임워크의 지향점과 겹치는 것 같지만, 이 생태계는 “애플리케이션을 동작시키기 위한 모든 구성 요소”를, End to End로 Kotlin으로만 작성하기를, 강요하지 않습니다. 우리에게는 세 가지 선택지가 있습니다.

⬆️ 이미지 출처: Kotlin Multiplatform for Cross-Platform Development | Jetbrains
첫 번째 옵션은 Logic의 일부를 공유하는 것입니다. (위의 두 번째 그림을 참고하면) Data / Business / Presentation Layer 중 일부만을 Kotlin으로 작성하고, 나머지 부분은 각 플랫폼에 맞는 네이티브 코드로 작성하는 것입니다.
두 번째는 UI를 제외한 모든 구성 요소의 네이티브 의존성을 제거하는 것입니다. 첫 번째 경우에서 플랫폼 간 공통 로직의 비율을 늘린 것인데요. MVVM 아키텍처를 적용한 모바일 애플리케이션을 예로 들어보죠.

⬆️ Data Layer에 해당하는 Model과 Presentation Layer에 해당하는 ViewModel은 Kotlin으로 작성하고, View는 각 네이티브 환경에 맞추어 작성한 경우의 다이어그램.
동일한 기능과 형태를 지닌 View가 각 네이티브 환경에 맞추어 작성되어 있는 형태입니다. 여기서 Compose UI와 SwiftUI 각각의 #1는 동일한 ViewModel에 의존하고 있습니다. (#2 View도 마찬가지입니다.) View를 제외한 모든 로직은 (Swift를 사용하지 않고) Kotlin으로 작성함으로써, 각각 네이티브 애플리케이션을 작성하는 것보다 코드량은 현저히 줄었으며, (각각 Material과 Cupertino의) 고유한 UI 특성은 살렸습니다.
세 번째 옵션은 UI까지 모두 Kotlin으로 작성하는 것입니다. 이를 위해서는 Jetpack Compose 기반의 Compose Multiplatform이라는 프레임워크를 사용해야 합니다. 사실 다른 Cross-platform 생태계와 경쟁하게 될 지점은 바로 여기입니다. 애플리케이션(Client Side)의 모든 Layer를 하나의 언어로 작성하기 때문인데요. 그렇지만 Kotlin이라는 생태계가 아직 이 부분에 있어서 강점을 지닌다고 이야기하기에는 시기상조입니다. Desktop Application이나 iOS의 경우에는 아직 불안정한 요소가 많기 때문입니다.
그러나 Kotlin Multiplaform의 방점은 세 번째 옵션에서 찍히는 것이 아니라고 글쓴이는 생각합니다. 완전한 네이티브 의존성에서 벗어나 애플리케이션을 개발할 때, Kotlin이 우리 손에 쥐어 주는 세 가지의 옵션은, (Kotlin Multiplatform이) 다른 Cross-platform의 결(結)과 분기되는 결정적인 지점이자 그 자체로 이 생태계가 가진 다양성의 표상입니다.
이렇게 (WORA와는 확실히 다른 의미의) 아래 문장을 충족시키기 위한 제반 조건은 모두 마련되었습니다.
Write Single Logic, Use it for Any Platform. 공통 로직을 작성하고, 어떤 플랫폼을 위해서든 동작하게 하자.
그러니 Kotlin의 다양성은 ‘Multiplatform’이라는 단어 안에도 존재합니다.
🔙 Kotlin Conf’ is Back!
잠시 숨을 고를 시간입니다. 지금까지 Kotlin이라는 커다란 섬, 가장자리를 숨가쁘게 달려 왔으니까요. (Kotlin은 실제로 핀란드 만(Gulf of Finland)에 있는 러시아 영유의 섬입니다. 이름만 봐도, 인도네시아 섬에서 그 명칭을 가져온, Java와 떼려야 뗄 수 없는 언어긴 하네요.)
⬆️ 넓고 넓은 12제곱킬로미터의 섬. 우리는 섬 한 바퀴를 거닐었습니다.
오직 텍스트를 향유하는 경험으로 말이죠.
이미지 출처: Kotlin Island: Google Maps
이 글은 지금까지 하나의 프로그래밍 언어가 가질 수 있는 다양성(Diversity)과 안정성(Reliability) 에 중점을 두고 논지를 전개해 왔습니다. 한 생태계의 미래를 바라보는, 앞으로의 텍스트에서도 그러할 것입니다. 위에서 다루었던 언어의 신뢰성을 높이는 10가지 요소를 다시금 톺아보며 (암스테르담에서와 판교, 모두의) 컨퍼런스 내용을 정리해 보겠습니다.
세 가지 키워드로 정리한, Kotlin의 미래로, 함께 가시죠.
Growing
⬆️ 연도별 Kotlin을 Primary Language로 사용하여 코드를 작성한 Github Repository의 수

(출처: Kotlin Conf'23 Opening Keynote)
- Tooling and Ecosystem : The availability of reliable development tools, libraries, and a supportive community can contribute to the overall reliability of a programming language. A strong ecosystem can help developers find solutions to problems and reduce the risk of bugs. => Tooling 그리고 생태계: Stable한 개발 도구, 라이브러리, 그리고 탄탄한 커뮤니티는 프로그래밍 언어의 신뢰성을 유지하는 데 기여합니다. 다양성이 보장된 생태계는 개발자들이 그들의 문제를 해결하는 데, 버그의 위험성을 스스로 낮추는 데 도움을 줍니다.
- Community and Code Reviews : An active and supportive developer community, as well as peer code reviews, can help identify and address reliability issues in software written in a particular language. => 커뮤니티 그리고 코드 리뷰: 안정적이고 활발한 개발자 커뮤니티는, 그리고 Peer Review는, 특정한 언어로 작성된 소프트웨어에 대한 신뢰성 문제를 발견하고 해결하는 데 도움을 줍니다.
우리는 앞서 프로그래밍 언어의 안정성(Reliablility)를 지탱하는 10가지 요소 중 두 가지만을 짚어 보았습니다. Type System과 Concurrency Support가 그것이었지요. ‘Growing’ 챕터에서는 Kotlin Code 그 자체에서 조금 시선을 돌려 보겠습니다. 숫자 그리고 키워드로 보는 프로그래밍 언어의 성장. 생태계와 커뮤니티에 대한 이야기. Kotlin 개발자들이 살아가는 코드 밖의 세계로, 공동체의 공간으로 여러분을 초대합니다.
One Million
2023년 4월 12일 기준, 1,000,000개가 넘는 Github 프로젝트에서 Kotlin을 기본 언어로 사용합니다. 2019년, 20만 개가 채 되지 않았던 것을 생각하면 가히 놀라운 성장세입니다. 그러나 Github에서 눈여겨 봐야 할 수치는 더 있습니다. 특정 프로그래밍 언어가 “개발자들 사이에서 꾸준히 논의의 대상이 되느냐” 그리고 “기여하고 싶은 프로젝트의 언어로 사용되느냐” 를 드러내는 두 요소인데요. 바로 Pull Request와 Issue입니다.
(Kotlin에 한정해서만) 이와 관련된 수치는 Kotlin Foundation이나 JetBrains가 공식적으로 발표한 바가 없고, 대신 Github 자체적으로 Public DataSet을 공개해 두었습니다. 그리고 이 방대한 데이터를 활용한 멋진 오픈소스도 존재하죠. 아래 두 그래프는 2012년 2분기부터 2023년 3분기까지 분기별로 Kotlin과 Swift가 Github의 전체 Pull Request와 Issue에서 Primary Language로 사용된 비율의 추이를 나타낸 것[5]입니다.
⬆️ Pull Request에서의 추이
⬆️ Issues에서의 추이
Kotlin
Swift
일부러 “네이티브 모바일 애플리케이션” 분야에서 직접적인 경쟁을 펼치고 있는 두 언어를 비교해 보았습니다.(참고로, 앞서 많은 비교를 일삼았던 Java와는 비교가 되지 않을 정도로, 오픈소스의 세계에서 Kotlin의 영향력은 아직 미약합니다.) 안정화 버전(LTS)이 2016년 처음 공개된 Kotlin은, 2014년 1.0의 Stable Release가 발표된 Swift보다 개발자들의 손에 녹아든 시간 자체가 조금 늦었습니다. 하지만 2019년 5월, 구글이 안드로이드 개발에서의 ’Kotlin-First‘를 선언함으로써, 판세가 역전됩니다. 꾸준히 안드로이드 생태계에서 영향력을 확장해 나가던 Kotlin은, Swift를 상대로, 2020년 1분기를 기점으로 두 수치 모두에서 우세를 거머쥐게 되었죠.
이러한 역전은 사실 예견되었던 일이며, 당연한 결과입니다. 태생부터가 Swift는 Apple 생태계를 위해 만들어진 언어입니다. Kotlin은 문법과 그 용도 모두 General-Purpose 언어죠. (이 글에서 수백 번 강조한 내용이기도 합니다. 보통 Swift도, General-purpose programming language - Wikipedia의 권위를 빌려도, 이에 포함되나, 단일 플랫폼 지향성이 짙다는 점에서 그 의미가 퇴색되는 부분이 있습니다.) One Million이라는 숫자를 넘어, Kotlin 생태계는 Java, JavaScript, Python과 같은, 거대한 커뮤니티를 가진 언어들과 경쟁해야 하는 숙제를 안고 있습니다. 앞에서 설명한 Kotlin이 가진 모든 요소들은 이러한 경쟁에서 사용될 무기들입니다. 그들의 여정을 앞으로도 더 지켜보시죠.
Android

안드로이드와 Kotlin은 떼려야 뗄 수 없는 관계입니다. 개발자들이 Github에 남긴 흔적들이 증명하듯, Kotlin 커뮤니티가 성장하는 데에는 Android의 역할이 결정적이었습니다. 글쓴이도 Kotlin의 존재를 Android 개발을 배우다 접했고, KotlinConf’23 - Keynote에서 JetBrains 사가 공개한 자료에 따르면 Kotlin 개발자의 66%는 안드로이드 네이티브 생태계에서 살아가는 사람들일 정도니까요.
1. Android Native 개발자의 97%는 Kotlin 사용에 만족합니다.
2. 상위 1000개의 안드로이드 앱 중 95%는 Kotlin으로 쓰여져 있습니다.
3. 상위 1000개의 안드로이드 앱 중 21%의 UI는 Jetpack Compose로 작성되어 있습니다.
구글이 안드로이드 애플리케이션 개발에서 Kotlin-First를 선언한 이후, 수많은 네이티브 프로젝트의 코드베이스(Codebase)가 다시 짜여지기 시작했습니다. 그렇지만 안드로이드의 총본산(總本山)에서 일종의 대원칙을 세웠다고 해서, 기존의 Java 생태계에 살던 개발자들이 그저 순순히 따라간 것일까요? 젊고 진취적인 이미지로 대변되는 개발자 집단은 사실 보수적인 면모도 지니고 있습니다. “이미 잘 작동하는 것처럼 보이는 코드”를 뜯어내는 작업은 절대 가벼운 결심에서 추동될 일이 아니기도 합니다.
왜 프로젝트에서 자바, 자바스크립트, C++가 아니라 코틀린을 사용하려고 하나요? 기업에서 진행하는 프로젝트에 코틀린을 사용하려고 한다면 작게는 팀원, 크게는 경영진까지도 설득할 수 있어야 할 것입니다. 이러한 설득에 가장 많이 활용되는 이유는 코틀린의 안정성(Safety)입니다. 코틀린은 다양한 설계 지원을 통해서 애플리케이션의 잠재적인 오류를 줄여 줍니다. '애플리케이션이 갑자기 종료되는 상황', '한 시간 동안 쇼핑하며 장바구니에 넣은 제품들이 결제가 되지 않는 상황'등을 직접 마주하지 않아도, 안정성이 왜 중요한지는 쉽게 이해할 수 있을 것입니다. 크래쉬(crash)가 적으면 사용자와 개발자 모두에게 좋고, 상당한 비즈니스 가치를 제공합니다.
마르친 모스칼라, 윤인성 역, 『이펙티브 코틀린(Effective Kotlin: Best Practices)』(2019), 도서출판인사이트, 2022, p.30.
결국 안정성, 안정성, 안정성입니다. 필요한 건 언어의 안정성을 증명할 수치(figure)입니다. 네이티브 생태계에서 살아가는 개발자들로 하여금 Kotlin으로의 마이그레이션을 유도하기 위한 구글의 노력 중 한 가지를 살펴보겠습니다.
Google Home reduces #1 cause of crashes by 33%
 "Efficacy and writing less code that does more is the ‘speed’ increase you can achieve with Kotlin.”
"Efficacy and writing less code that does more is the ‘speed’ increase you can achieve with Kotlin.”
Kotlin을 사용할 때의 장점은 더 적은 코드와 효율성이 만들어내는 속도 향상입니다.
- Jared Burrows, Software Engineer on Google Home
Google Home은 Google Nest를 포함한 IoT 가전제품을 조작하기 위한 애플리케이션입니다. 기능만 짧게 훑어 보아도 엄청난 코드량이 눈앞을 서성입니다. 당연히, 백만 줄이 넘어가는(over a million lines of code) 소스(Source)를 뒤집기란 쉬운 일이 아닙니다. 큰 결심이 필요한 일이지요. (지금은 그 비율이 훨씬 늘었겠지만,) Google Home 개발팀은 2020년 6월까지 전체 코드의 30%를 Kotlin으로 대체했습니다. val를 이용한 불변 데이터 관리, 스마트 캐스팅(Smart Casting), 코루틴(Coroutine), 그리고 수많은 Jetpack 라이브러리가 리팩터링(Refactoring) 전투에서 그들의 무기가 되었지요.
당연히 2020년에 7월에 작성된 위 글에서는 ’30%’ 정도의 변화가 이끌어낸 결과에 대해서 다루고 있음에도, 그 내용은 사뭇 놀랍습니다. 구체적인 수치로 살펴보면 다음과 같습니다.
먼저, kotlin-parcelize 플러그인과 data class를 이용해 코드량을 획기적으로 줄인 사례(80% 감소)가 주목할 만합니다. Kotlin의 간결함을 나타내는 사례로 앞에서 data class를 언급했으니, 여기서는 안드로이드에 의존성을 가진 인터페이스에 대해서 잠깐 다뤄보겠습니다. Kotlin 생태계 전체를 포괄하는 이야기가 아니므로, 아래 초록 배경의 블록은 독자 분들의 필요에 따라 흘겨 읽으셔도 좋습니다.
직렬화 그리고
ParcelableSerializable Objects
To serialize an object means to convert its state to a byte stream so that the byte stream can be reverted back into a copy of the object.
A Java object is serializable if its class or any of its superclasses implements either thejava.io.Serializableinterface or its subinterface,java.io.Externalizable.
객체를 직렬화한다는 건 해당 객체의 상태를 ByteStream으로 변환하여 그 ByteStream을 다시 객체의 복사본으로 되돌릴 수 있도록 하는 것을 의미합니다.
Java 객체는 해당 클래스나 상위 클래스 중 하나가java.io.Serializable인터페이스 또는 그 하위 인터페이스인java.io.Externalizable을 implement하는 경우 직렬화됩니다.
직렬화(Serialize)는 하나의 프로세스에서 다른 프로세스로, Byte-Stream 형태로 객체를 내보내야 할 때 사용합니다. Android에서도 화면 설계에서 프로세스 간 객체의 전달이 필요한 경우, 이에 따른 직렬화 메커니즘이 요구되며, 이러한 메커니즘을 OS 의존적으로 구현한 것이Parcelable객체입니다.
Parcelable and bundles
ParcelableandBundleobjects are intended to be used across process boundaries such as with IPC/Binder transactions, between activities with intents, and to store transient state across configuration changes.
Parcelable과 Bundle 객체는 IPC / Binder 트랜젝션과 같이 프로세스 경계를 넘나드는, Intent가 존재하는 여러 Activity 사이에서 사용되거나, Configuration 변경 중 일시적인 상태를 저장하기 위해 사용됩니다.
Bundle이 간단한 값 데이터를 담아 Activity 사이를 오가는 것과는 다르게, Complex한 형태의 객체가 다른 프로세스로 전달되기 위해서는 해당 클래스에ParcelableInterface를 Implement해야 합니다. 그렇게 직렬화가 마무리되면, OS는 Binder 매커니즘을 통해 프로세스 간 통신을 진행합니다. (그러한 통신이 애플리케이션 내에서 진행되든 밖으로 나아가게 되든 말이지요.)

Activity 사이의 데이터 전달 뿐 아니라, IoT 기능을 지원하는 Google Home 애플리케이션의 특성상, (추측하건대) 외부의 서비스 서버(시스템 프로세스)를 활용해야 하는 경우가 많을 것입니다. (SerializableInterface을 Implement해 명시적인 모든 작업을 Compiler에 떠넘기는 대신에, 수많은 Parcel 객체를 생성해야만 하지요.)
여러 프로세스를 오가는 속도와 안정성을 위해, Android의Parcelable인터페이스는 역직렬화(Deserialization)을 진행할 때의 Reflection을 없앤 대가로, 수많은 Bolierplate를 생성해 냈습니다.
In such cases, the custom class should implement Parcelable, and provide the appropriatewriteToParcel(android.os.Parcel, int)method.
It must also provide a non-null field calledCREATORthat implements theParcelable.Creatorinterface, whosecreateFromParcel()method is used for converting the Parcel back to the current object.
(Complex한 형태의 객체가 프로세스를 오가는) 이러한 경우에는, 우리의 Custom Class는 Parcelable Interface를 implement해야 하며, 적절한 writeToParcel 메서드를 구현해야만 합니다. 또한 Parcelable.Creator Interface를 implement하는 null이 아닌 CREATOR 필드를 생성해야 하고, 여기에 존재해야 하는 createFromParcel 메서드는 Parcel 객체를 기존 객체로 변환하는 데 사용합니다.
@ParcelizeAnnotation은 이러한 Bolierplate를 제거하는 데 기여했습니다. 그리고 간결한 문법을 제공하는data class와 결합하며 생산성도 덩달아 크게 증가했지요. 위와 같은 예시는, 직렬화가 필요하다면 Parcelable 인터페이스를 구현하도록, 그리고 간결함을 제공하는 플러그인을 사용하도록 유도하는, 결국은 Android 개발자들을 Kotlin 생태계로 끌어당기려는 노력의 일환이라고 할 수 있겠습니다.
그리고 NullPointerException의 감소입니다. 위 포스트에 따르면 Google Play Console에서 가장 흔한 Crash는 NPE인데요. Kotlin을 도입함으로써 사용자 경험을 근본적으로 개선할 기회를 얻은 것입니다.
이는 Kotlin이 “Potentially null variable”에 대해 엄격한 문법적 규칙을 적용하기 때문인데요(Nullable의 개념에 대해서는 앞에서 다루었으니 여기서는 촌음을 아끼기 위해 생략하겠습니다.)
Kotlin Compiler의 필터가 덧씌워지지 않은, 원래의 JVM에서는 어떤 방식으로 변수(variable)을 다룰까요? 어떻게 변수를 다루길래 백만 불짜리 실수가 계속해서 발생하는 것인지, 그 근원을 잠깐 살펴보겠습니다.(아래 블록의 내용은 StackOverflow의 What is a NullPointerException, and how do I fix it?의 답변을 재구성한 것입니다.)
What is a NullPointerException, and how do I fix it?
Java 생태계에는 두 가지 타입의 변수가 있습니다. Primitive와 Reference가 바로 그것이죠.
흔히 번역된 투로 각각 원시 타입과 참조 타입이라 부르지요.

Primitives는 Data를 직접 담을 수 있는 변수입니다. 이는 해당 Data를 직접적으로 다룰 수 있음을 의미(manipulate directly)합니다. Java에서는int,short,long,char,byte,double,float,boolean의 8개의 타입이 이에 해당됩니다.
위의 코드는 컴파일 에러를 야기합니다. Primitive인

x에 데이터를 할당하지 않은 채로,y를 초기화하는 데x를 직접 활용하려고 했기 때문입니다. 모든 Primitive는 다루어지기 이전에 초기화되어야 합니다. (have to be initialized to a usable value before manipulated)
References는 객체(Object)의 메모리 주소를 담는 변수입니다. 객체를 '다루려면,' 일종의 Dereferencing이 필요합니다..을 이용해 Field나 Method에 접근하거나,[]를 통해 Array를 인덱싱하는 등이 이에 해당됩니다.References는 Primitives와 다르게, 초기화하지 않아도 특정한 값을 가집니다. 문제의

null은 여기서 발생하는데요. Java 컴파일러는 할당이 이루어지지 않은 Reference에 자동으로null을 부여합니다. null은 기본적으로 변수가 어떤 메모리 주소도 가리키고 있지 않음을 의미합니다. 특정한 객체의 메모리 주소가 할당되지 않은 References를 Dereferencing할 때, 발생하는 Runtime Error가 바로NullPointerException인 것입니다.
Kotlin은 null에 대한 접근을 Runtime 대신 Compile Time에 수행하게 하도록 설계되었습니다. Referencing은 기본적으로 Runtime의 몫인데, 이게 어떻게 가능했는지는 Codelab의 예시를 통해 자세히 살펴보겠습니다.
Use nullability in Kotlin: Handle nullable variables
Part of "Access a property of a nullable variable"
위 코드를 컴파일하면, 아래와 같은 결과가 나옵니다.


String?과 같은 Nullable 객체에는 오직?.를 이용한 Safe Call이나!!.를 통한 Non-Null Assertion Call을 사용해서만 접근할 수 있습니다.
컴파일 에러는 말 그대로 코드를 컴파일할 수 없을 때 발생합니다. 즉, 문법적으로 올바르지 않은 코드를 작성해 생기는 참사지요. Null Safety를 위해 Kotlin은 엄격한 문법적 규칙(Syntatic Rule)을 적용합니다. 변수가null의 가능성을 가질 때 (정확히는 변수가 아무런 객체의 메모리 주소도 가리키고 있지 않을 가능성이 있을 때(When referencing nothing)), 접근 자체를 거부함으로써 "문법적 사고"를 미연에 방지합니다.
이를 바꾸어 말하면, (Kotlin에는 Primitive Type이 존재하지 않으므로) 특정 변수의 멤버에 접근할 수 있다는 건, 그 변수는null의 값을 가질 수 없다는 의미입니다.Due to the null safety nature of Kotlin,
such runtime errors are prevented because the Kotlin compiler forces a null check for nullable types.
Null check refers to a process of checking whether a variable could be null before it's accessed and treated as a non-nullable type.
Null Safety를 지원함으로써
이러한 Runtime Error는 예방됩니다. Kotlin 컴파일러가 Nullable 타입에 대한null체크를 강제하기 때문인데요.
여기서 Null Check란 Nullable 변수에 접근하고 이를 Non-Nullable처럼 다루기 이전에 변수의 null 여부를 체크하는 프로세스를 의미합니다.
다양성 속의 안정성. 이렇게 Kotlin의 엄격한 실용주의적 설계 원칙은 Android에 결합되어 그 빛을 발합니다. 추후에 “Android 생태계는 왜 Kotlin을 선택했는가?”의 주제로 관련 내용을 좀 더 톺아보겠습니다.
이제 진정 새로운 Kotlin에 대한 이야기를 나눌 시간입니다. 함께 가시죠.
New Compiler
해당 섹션은 YouTube 채널 Kotlin by Jetbrains 에서 업로드한1. What Everyone Must Know About the NEW Kotlin K2 Compiler 2. Crash Course on the Kotlin Compiler by Amanda Hinchman-Dominguez 3. The New Kotlin K2 Compiler: Expert Review세 영상을 참고해 작성되었습니다.
We’ve been working on a new frontend for the Kotlin compiler (code-named “K2”) for quite a while.

( ... )
The new frontend is already available for preview – we’re continually polishing and stabilizing it and plan to make it the default compiler frontend in a future Kotlin release.
We’ve decided to name this future release Kotlin 2.0.
The K2 Compiler Is Going Stable in Kotlin 2.0 | Kotlin Blog
Kotlin 2.0의 릴리즈(Release)는 곧 새로운 컴파일러, 코드네임 “K2”의 안정화 버전을 적용한 Kotlin의 등장을 의미합니다. 정확히는 새로운 컴파일러 프론트엔드(Frontend)를 장착한 Kotlin인데요. 여기서 컴파일러 전체를 조금씩 수리한 것(Refactoring)이 아니라, “프론트엔드”만 완전히 새로 작성하였다는 사실(Rewriting)에 주목해야 합니다. (JVM 바이트코드나 JavaScript ES5를 타겟으로 하는) 컴파일러 백엔드(Backend)의 경우, 버전 1.5와 1.6에 걸쳐 업데이트되었습니다. 이는 Kotlin 전체 생태계에서 마이너 업데이트(Minor Version Update)에 포함되는 데 그쳤지요. 하지만 2.0의 릴리즈는 Kotlin 생태계 전체에 있어, 컴파일러 프론트엔드의 변화가 큰 의미를 지니게 됨을 그 자체로 암시하고 있습니다. 컴파일러의 어떠한 변화가 Kotlin의 Major한 움직임을 추동한 것일까요? 먼저, 기존의 컴파일러가 어떤 방식으로 작동하는지 살펴보겠습니다.
How Compiler Works
인간의 직업으로 따지면, 컴파일러는 일종의 번역가입니다. 서로 다른 언어의 세계를 연결하는 매개체로서의 역할을 수행하지요. 하지만 인간의 언어와 달리, 프로그래밍의 세계에서는 고수준(High-level)과 저수준(low-level)이라는 딱지가 붙기 십상이며, 컴파일러는 오로지 위에서 아래로의 번역만을 수행할 뿐입니다. 이는 컴퓨터가 우리의 생각보다 굉장히 단순한 일만을 수행할 수 있기 때문에, 인간의 사고 수준이 아직 기계보다는 고등하다는 인식에서 나온 표현이라 할 수 있겠습니다. 다시 문장의 방향키를 돌려서, 극도로 추상화된 인간의 사고에서 창발된 “고수준”의 프로그래밍 언어에서, 이보다 더 명료할 수 없는 바이너리(Binary)로의 여정까지 Kotlin 컴파일러는 어떤 일들을 할까요?
Background
해당 블록은 컴파일러를 다룰 때 빼놓을 수 없는 명저(名著, Modern Classic)인 The Dragon Book[6]의 내용을 기초로 작성되었습니다.
컴파일러는 크게 두 부분으로 구성됩니다. 프론트엔드(Frontend)와 백엔드(Backend)가 바로 그것인데요.

Washington CS Course 401: Abstract Syntax Parsing Trees의 세번째 슬라이드를 재구성.
컴파일러에서 프론트엔드(Frontend)는 개발자가 입력한 코드를 Input으로 받습니다. 그리고 Syntax Tree(IntelliJ Platform 계열에서는 Programming Structure Interface라고 부르는 것)에 *Symbol Table를 덧붙여 백엔드(Backend)로 내보냅니다. 백엔드(Backend)는 프론트엔드의 Output을 받아 Machine Code, JavaScript, 또는 JVM Bytecode, 즉 Target Code로 변환하는 역할을 수행합니다. 바로 타겟으로 변환하여 최적화 단계를 진행하는 경우도 있고, 프론트엔드에서
Intermediate Representation, 줄여서IR을 만들어주는 경우, 이것을 타겟으로 변환하는 컴파일러 백엔드도 있습니다.IR을 최적화하는 단계를 미들엔드(Middle-end)로 분리할 수 있습니다. Kotlin 컴파일러가 어떻게 일하는지 다루는 이 글에서는 The Road to K2 Compiler | Kotlin Blog의 내용을 준용하여 해당 과정(Optimizing IR)을 백엔드에 포함시킵니다. 참고해 주세요.
* Symbol Table : 컴파일러 또는 인터프리터와 같은 Language Translator에서 사용하는 자료구조입니다. 각각의 Identifier, Constant, Procedure, Function이 코드 내에서 어떻게 선언하였고 사용되었는지 연결하는 역할을 맡고 있지요.
Parser
컴파일러가 코드를 처음 읽을 때, 가장 먼저 하는 일은 개발자가 정확히 무엇을 작성했는지 파악하는 것입니다. 이를 위한 첫 번째 단계는 코드를 쪼개는 것입니다. 정제된 언어로 Tokenize한다고 하는데요.
컴파일의 첫 단추를 꿰는 Parser의 역할은 코드가 잘 돌아가는지 파악하는 게 아니라, 컴파일러의 다른 부분이 코드를 잘 분석하고 검증할 수 있도록 만드는 것입니다. Computer Scientific하게 다시 말하면, Tokenize된 Node들을 Tree의 형태로 정리해서 Semantic Analyzer로 넘겨야 하지요.
1. Lexical Analysis: 규칙에 맞게 자르기
Lexical의 사전적 의미는 “relating to words or vocabulary”, 즉 단어나 어휘에 관련되어 있다는 뜻입니다. 이를 준용해서 Lexical Process의 역할을 설명해 보면, 아직 아무런 의미도 가지지 못하는 문자의 집합을 Kotlin의 어휘에 맞게 재구성하는 것입니다.
이를 위해 Kotlin 컴파일러의 Parser는 KotlinLexer 객체를 생성합니다. 이 Lexer는 우리가 작성한 코드를 Token의 집합으로 치환합니다. 이 Token들은 KtTokens interface에 정리되어 있는데요. 여기에서 return이라는 키워드는 이렇게 정의되어 있습니다.
public interface KtTokens {
...
int RETURN_KEYWORD_Id = 33;
...
KtKeywordToken RETURN_KEYWORD = KtKeywordToken.keyword("return", RETURN_KEYWORD_Id);
}
따끈따끈하게 막 생성된 토큰들은 KotlinExpressionParsing 객체가 Expression Node의 set으로 변환합니다. 이러한 집합을 한데 모아 ASTNode 객체를 통해 PSI Tree를 구성합니다. (AST와 PSI가 무엇인지는 아래의 ‘트리 만들기’ 부분에서 좀 더 다뤄보도록 할게요.) 그에 앞서
IntelliJ Platform Plugin의 Document를 보며 RETURN_KEYWORD가 어떻게 PSI Tree의 일부가 되는지 살펴봅시다.
Parser Implementation
compiler/psi/src/org/jetbrains/kotlin/parsing/KotlinExpressionParsing.java/* * "return" getEntryPoint? element? */ private void parseReturn() { assert _at(RETURN_KEYWORD); PsiBuilder.Marker returnExpression = mark(); advance(); // RETURN_KEYWORD parseLabelReferenceWithNoWhitespace(); if (atSet(EXPRESSION_FIRST) && !at(EOL_OR_SEMICOLON)) parseExpression(); returnExpression.done(RETURN); }JetBrains IDE에서 (Kotlin을 포함한) Language Plugin은
PsiParser인터페이스의 구현체로서 Parser를 제공합니다. 그리고 이는ParserDefinition.createParser()메서드의 리턴값이죠. 그리고 Parser는PsiBuilderClass의 인스턴스를 Input으로 받지요.PSIBuilder의 인스턴스는 KotlinLexer 객체가 생성한 KtToken의 Stream을 받아 구축 중인 AST의 중간 상태를 유지하는 데 사용됩니다.(당연하게도) Parser는 Lexing Process에서 생성된 모든 Token을 처리해야만 합니다. (Stream이 끝에 닿을 때, 즉
PsiBuilder.getTokenType()이null을 반환할 때까지를 의미합니다.) 설사 생성된 Token이 문법에 어긋나더라도 말이지요.그렇게 Token의 Stream을 받아들인 Parser는 내부적으로 Marker (
PsiBuilder.Marker의 인스턴스) 의 Pair를 맞춰주는 일을 수행합니다. 각각의 Pair는 KtToken의 범위를 결정하고, 이는 AST의 단일 노드를 확정합니다. 하나의 Pair가 다른 Pair 안에 중첩되어 있으면, 바깥 Pair가 안쪽 Pair의 부모 노드가 됩니다. Marker의 Pair, AST 노드의 타입(Type)은 End Marker가 세팅되면 결정됩니다. 이는PsiBuilder.Marker.done()를 호출하는 방식으로 이루어지죠.
(Document의 이미지를 준용해) 아래 도식은
return 2 + 3이라는 (굉장히 단순한) 코드가 Tokenize되어 Marker의 Pair가 맞춰지기까지의 과정을 나타낸 것입니다. Token의 Type은 Kotlin에 맞추어 변경했으니 참고해 주세요.

이제 트리를 만들기 위한 준비를 모두 마쳤습니다.
{kind=link}
2. Syntax Analysis: 트리 만들기
위에서 AST는 Abstract Syntax Tree를 이야기하는데요. Background에서는 뭉뚱그려 Parser의 Output이 Syntax Tree라고 언급했지만, 정확히는 Abstract(추상화된)이라는 수식어가 붙어야 합니다. 그러니, Abstract Version이 존재하므로, 추상화의 대상인 Concrete Version도 존재하겠죠. 그렇다면 이 두 형태의 Syntax Tree에는 어떤 차이가 있을까요. Eli Bendersky의 블로그 포스트인 Abstract vs. Concrete Syntax Trees는 명쾌한 해답을 제공합니다. 글쓴이가 그 내용을 간추려 보았습니다.
Abstract vs. Concrete Syntax Trees
return a + 2이번에도 (분석하기 비교적 쉬운)
return키워드를 가져와 봤습니다. 위 코드를 분석해 Concrete한 방식으로 문법의 나무를 만들면 어떻게 될까요. 일단 Dragon Book에서 이야기하는 정의부터 보시죠.A parse tree(= CST) pictorially shows how the start symbol of a grammar derives a string in the language. [6]
Parse Tree는 프로그래밍 언어에서 하나의 문자열이 Start Symbol에 의해 (문법적으로) 어떻게 산출되는지 시각적으로 나타냅니다.여기서 Start Symbol이 뭘까요? Blog에서는 자세히 설명해 주지 않지만, IBM Documentation에서는 이렇게 이야기합니다.
The first nonterminal symbol defined in the rules section is called the start symbol. This symbol is taken to be the largest, most general structure described by the grammar rules. For example, if you are generating the parser for a compiler, the start symbol should describe what a complete program looks like in the language to be parsed.
Grammar Rules Section에서 가장 처음 정의되는 Nonterminal Symbol을 Start Symbol이라고 합니다. Start Symbol은 Grammar Rule에서 설명하는 가장 크고 중요한 구조로 취급됩니다. 예를 들어, 컴파일러가 Parser를 구성할 때, Start Symbol은 프로그램이 어떻게 구성되는지 서술해야 하는 역할을 맡습니다.Kotlin Compiler가
return이라는 키워드를 해석할 때 찾는 사전의 단락은 아래와 같습니다. 정답부터 이야기해 보자면, 여기서 nonterminal symbol은jumpExpression과expression입니다. GeeksforGeeks의 표현을 빌리자면, 구문의 생성에는 관여하나 구문의 구성 요소는 아닌 Symbol(those symbols which take part in the generation of the sentence but are not the component of the sentence)이지요.jumpExpression : 'throw' expression | ('return' | RETURN_AT) expression? | 'continue' | CONTINUE_AT | 'break' | BREAK_AT ;조금 익숙한 형태로 풀어가 볼까요. 정말 간단한 영어 문장을 생각해 봅시다. SSubject + VVerb + OObject 같은 딱딱한 문법 구조 말고, 축구 게임을 떠올려 봅시다. (개발자들에게 항상 뛰어난 영감을 제공하는 stackoverflow의 비유를 차용해 보았습니다) 리오넬 메시가 (늘 그랬듯이) 좋은 패스를 했습니다. ‘패스’라는 행위(action)를 ‘선수의 이름’(player)과 묶어 movement라고 이름 붙인 뒤, 프로그래밍 언어의 문법 체계대로 옮겨 보면 다음과 같습니다.
정리해 보지요. 하나의 문장이 게임에서

movement라고 인식되려면,player와action으로 구성되어야 합니다. 그리고player는name과surname으로 구성되어야 하지요. 또한action은'passes','crosses','shots'중 하나여야만 합니다. 하지만'passes'에서 가지가 더 뻗어나가지는 않지요.'passes'와 마찬가지로, 실제로 우리가 작성하는 코드, 이 예시에서는 통틀어 "Lionel Messi passes"라는 텍스트는 나무가 가진 수많은 가지들의 종단점(terminal point)에 위치합니다. 아래는 나무의 예시입니다.Non-Terminal Symbol은 구문의 생성에는 관여하나, 구문의 구성 요소는 아니다. 이를 풀어서 이야기하면, Non-Terminal Symbol은 컴파일러가 우리가 작성한 코드를 해석하는 데 필요한 일종의 표지인 것입니다. 그와 달리 Terminal Symbol은 Grammar Rule에 맞게 쪼개진 Token일 뿐이지요. Kotlin Grammar Rule에 맞추어,

return a + 2로 Concrete한 나무를 만든다면,위의 그림과 같습니다. 나무에서

return,a,+,2를 제외한 모든 Element는 non-terminal symbol인 것이지요. Sentence에서 가장 처음 등장하는 non-terminal symbol이 Start Symbol이니, 여기서는jumpExpression이겠네요. 결국 AST, Parse Tree는 Start Symbol이 어떻게 Terminal Point(우리가 작성한 String)까지 도달하는지를 산출한 결과입니다.이렇게 짧은 코드임에도 불구하고, 이 정도의 복잡도를 가진 나무로 치환된다면, 아무리 컴퓨터라도 같이 일하기 어려운 형태(not a very useful representation to work with)임은 확실합니다. 우리에게는 코드(우리가 작성한 문자열에 가까운 무리)에 가까운 나무보다, 컴파일러에게 가까운 나무가 필요합니다. 그래서 등장하는 형태의 나무가 Abstract Syntax Tree이죠.
Abstract syntax trees, or simply syntax trees, differ from parse trees because superficial distinctions of form, unimportant for translation, do not appear in syntax trees. [6]
Abstract Syntax Tree, 혹은 간단히 Syntax Tree라 불리는 구조는 Parse Tree와 다른 형태를 지닙니다. (문법적) 형태의 피상적인 구별점, 즉 번역에 필요없는 요소들은 생략됩니다.이번에는 C99로 작성된 같은 내용의 코드를 보시죠.
return a + 2;Kotlin 코드와는
;정도의 차이만 보이는 위의 C99 코드는 pycparser를 사용하면 다음과 같은 도식으로 치환됩니다.

AST는 문법적인 잡동사니(Clutter)를 보여주진 않지만, 조각난(parsed) 문자열을 구조적으로 표현합니다. 코드를 “분할하는 데” 필요할 수 있는 정보이긴 하나, “분석하는 데” 필요한 정보를, 일종의 문법적 잡상을 제거한 형태를 보여주죠.
문자열(String)로 이루어진 코드(Code)를 Binary로 이끌어야 하는 험난한 여정에 Concrete한 나무, Parse Tree는 짊어지기 너무나 무겁습니다. 그래서 Parsing하는 문자열이 Grammar Rule을 준수한다고 판단되면, Concrete한 정보들은 버려집니다. 다시 정리하면, CST는 이 문자열이 해당 프로그래밍 언어의 문법에 어긋나지 않는지 파악하기 위해, 컴파일러가 가지는 일련의 사고 흐름을 시각화한 것입니다. 그리고 AST는 컴파일러가 CST를 만들며 열심히 문법적 오류를 검사한 결과, 최종적으로 판단한 코드의 실체적인 구조인 것입니다.
이제 토큰들은 서로가 가진 끈을 묶어 나무가 되었습니다.
대부분의 컴파일러에서, Parser는 Abstract Syntax Tree를 생성하고 이를 Semantic Analyzer로 전달합니다. 하지만 Kotlin은 PSI(Program Structure Interface) Tree를 만드는데요. 여기서 PSI는 JetBrains가 만든 추상화 도구입니다. JetBrains의 모든 IDE에서 작성되는 텍스트, 코드, 언어를 핸들링하기 위한, 일종의 무겁고도 Generic한 Syntax Tree이지요. PSI는 마냥 가볍지 않은, Concrete한 형태와 Abstract한 형태의 중간에 있습니다. CST에 가까운 점은 형식적인 요소(Formal Representation)까지 나무에 포함시킨다는 것입니다. (여기서 형식적인 요소라 하면, 세미콜론 (;)소괄호(())와 같은 문법적 잡상(Clutter)이죠) 각각의 노드에 부가적인 정보가 첨가되며, nonterminal symbol이 적다는 면에서는 AST에 가까운 형태를 취합니다. 그렇다면 PSI Tree는 어떻게 AST로부터 파생되는 걸까요.
이미 Lexer에서 나온 Token은 Marker들이 감싸안아, 이미 그 타입이 결정된 ASTNode의 형태로 존재합니다. 그 노드들의 상하 관계를 나타낸 도식이 위 그림의 오른쪽 나무(Abstract Syntax Tree)입니다. 그리고 AST Node는 Factory Class(ASTWrpperPsiElement)로 보내져 일종의 포장지(Wrapper)를 만드는 데 사용됩니다. 그것이 바로 PSI element인 것이죠. 여기서의 PSI element는 PSI Tree의 Composite Node로 기능합니다. 그리고 Composite Node (Element) 아래에 Terminal Symbol (Token)이 자리하게 되면, PSI Tree가 됩니다.
PSI Tree represented as Concrete Syntax Tree
fun hello(user: string) = println("Hello, $user")PSI는 기본적으로 AST의 뼈대를 갖춘 상태로 출발합니다. 여기서 뼈대라 하면 AST Node로부터 변환된 PSI Element를 의미하죠. 즉 Composite Node입니다. 아래 다이어그램은 순수하게 AST Node만을 가지고 만들어낸 트리의 형상입니다.

ASTNode를 Composite Node로 활용해 커다란 가지들을 뻗치게 된 PSI Tree는 확장을 시도합니다. AST는 기본적으로 Top-level Element들만을 가지고 있는 형태거든요. 순수하게 Object-Oriented로 작성된 Source를 가정했을 때, AST는 클래스(Class), 메서드(Method), 필드(Field) 등에 대한 접근 권한만을 가지고 있는 나무인 것이죠. PSI Layer는 AST Node에 특별한 힘을 부여합니다.
PSI element를 생성하는 Factory Class는 일종의 토큰을 쥐어주는데요. 정확히는 이미 ‘정해진 타입’으로 둘러싸인 AST Node 안에 있던 -오래 전 Lexical Analysis에서 생성되었던- 토큰입니다. 이 토큰들을 활용해 온전히 AST의 형태이던 PSI Tree는 CST에 가까운 모습으로 변모합니다. (WhiteSpace가 포함되는 건 물론입니다.) 또한 이 과정에서 코드에 다양한 Semantic Information (타입 정보, 스코프 정보, 라이브러리 등)을 추가합니다. 원래 코드에 Lexing과 Tokenize, Abstraction을 진행하여 AST에 이르고, PSI로 변환되는 과정을 도식화한 아래의 그림이 이해를 도울 듯 합니다.

최종적으로
hello함수의 PSI Tree는 다음과 같습니다.


모든 컴파일러 프론트엔드의 Parser는 AST를 생성합니다. 그리고 이를 Semantic Analyzer로 전달하는 역할을 수행하죠. 하지만 Jetbrains IDE에서 컴파일되는 모든 언어들은 – Kotlin을 포함해 – PSI (Programming Structure Interface)라는 독특한 구조를 생성하게끔 되어 있습니다. 그리고 (v2.0 이전의) Kotlin 컴파일러는
BindingContext라는 일종의 Map과 함께 PSI를 프론트엔드 전역에서 활용했습니다. 이제 지도를 찾아 모험을 떠날 시간입니다. 이제 코드의 Structure를 모두 분석했으니 어떤 Semantic이 숨어 있는지 찾아나설 차례입니다.
Semantic Analyzer
트리를 만들기 위해 수많은 일들을 했지만, 아직 이 문자열에 어떠한 의미도 부여되지 않은 상황입니다. 직역하여 ‘의미 분석기’의 뜻을 가지는 Semantic Analyzer의 역할은, 정확히는, 손에 쥐여진 ‘나무’에 의미를 부여하는 일입니다. 전체 컴파일러에서 이 부분이 가지는 임무는 크게 세 가지인데요. 하나씩 살펴보도록 하지요.
1. Call Resolution : 어디서 오셨나요|
|
옆의 코드에서 세 차례 등장하는 kevin은 아직 연결되어 있지 않습니다. Syntax Tree에서 독립적으로 존재하는 하나의 노드(Node)일 뿐, 그저 문자열일 뿐이지요. Semantic Analyzer는 먼저 동일한 메모리 주소를 가리키는 Variable 그리고 Parameter를 찾아내야 합니다. 즉, 두 번째와 세 번째 kevin이 함수에서 처음으로 등장하는 kevin과 동일함을 파악해야 한다는 것이죠. |
|
|
그렇다면 타입(Class 혹은 Interface)을 의미하는 String의 경우에는 어떨까요. 이 친구들도 Syntax Tree에 존재하는 Node일 뿐입니다. 아무런 의미도 지니지 않고 있죠. 프론트엔드가 만들어야 할 Table에는 타입에 대한 정보가 필수로 포함됩니다. 여기서 Life는 같은 .kt 파일에 존재하는 빈 인터페이스를 가리키며, Human은 Life를 상속(inherit)받은 클래스를 의미합니다. Type Argument (예를 들어 val num : Int에서의 Int)도 이와 같은 방식으로 Resolution을 진행합니다. |
|
|
이제 함수를 찾을 차례입니다. 코드를 쓰고 읽는 우리는 kevin이 Human이라는 클래스의 인스턴스임을 알고 있습니다. 그리고 hello()가 Human이라는 클래스의 메서드임을 인지하고 있지요. 하지만, 이 단계에서의 컴파일러는 'hello'라는 문자열만을 손에 들고 있을 뿐, 아무런 맥락을 지니고 있지 못합니다. 컴파일러는 hello()가 멤버 함수(member)인지, 확장 함수(extension)인지, 함수 타입의 프로퍼티(property of function type)인지 모릅니다. 또한 같은 모듈에 존재하는지, 다른 모듈에 존재하는지, 특정 라이브러리에 존재하는지 알지 못하죠. 그러니 Semantic Analyzer는, 단 하나도 빠짐없이, 주어진 이름(hello)에 해당하는 모든 함수를 찾아내야 합니다. 그리고 수많은 함수 중 가정 적절한 것을 골라내어야 합니다. 이것이 바로 Semantic Analyzer에서 가장 핵심적인 부분이며, 가장 많은 시간이 소요되는 작업이 바로 적절한 함수를 찾아내는 일인 이유입니다.
|
또 다른 Semantic Analyzer의 중요한 역할은 타입을 추론(Type Inference)하는 것입니다. Kotlin에서 Type Inference가 필요한 순간은 크게 두 가지로 구분지을 수 있죠. 컴파일러는 이 모든 경우에 대비할 수 있어야 합니다. 물론, 빠른 속도로 말이지요. Kotlin의 Type Inference를 이해하기 위해서는 Smart Cast에 대한 이해가 우선합니다. 간단한 예시와 함께 살펴 보겠습니다.
Smart Cast in Kotlin
컴파일러가 Smart Cast의 산을 넘으면, 마주하는 추론의 갈림길은 두 갈래입니다. Local Type Inference와 Function Signature Type Inference가 그것이죠.
- 변수를 초기화하는 경우 (Initialize a variable)
fun main() { val num = 1 // Inferring the type 'Int' val name = "Kevin" // Inferring the type 'String' }
타입 추론을 언급할 때 가장 흔히 인용되는 예시입니다. 어떤 그릇에 값(value)을 담을 것인지 코드에 명시적으로 작성하지 않은 경우 일어나는 추론이죠. Kotlin에서는 Primitive Type으로 보이는 값 - Int, Char, Boolean 같은 - 이 모두 객체입니다. 그러니 이 값이, 어떤 클래스의 인스턴스에 담길 것인지, 컴파일 타임에 정해야 합니다.
- 제너릭 (Generics)
fun <T> makeSerializedSet(element: T) : List<T> = listOf(element) val numberSet = makeSerializedSet(17) // Inferring the set of 'Int'
제너릭(Generic)도 빠질 수 없죠.
- 함수의 리턴 타입 (Return Type of a Function)
fun multiply(num1: Int, num2: Int) = num1 * num2 // Inferring the return type as 'Int'
- 람다 식 (Lambda Expression)
val divide = { num1: Int, num2: Int -> a + b } // Inferring the function type as '(Int, Int) -> Int'
BindingContext라는 방대한 지도 생성하기
Kotlin K2 Compiler Overview : Main Differences
Another problem with the old compiler was the
BindingContext. It is the huge collection of hash tables/maps that stores all the binging information. So for instance, if we would want to look up the variable referenced in string interpolation, the old compiler needs to do 2 map lookups. The new K2 compiler does not do so, but rather, it relies on the tree data structure in FIR. It is faster to access the node member value of the tree than to do 2 searches inside the huge hash table data structure.
기존 컴파일러가 가졌던 또다른 문제는 바로 BindingContext입니다. 이는 수많은 정보를 담은 HashTable과 Map의 거대한 집합입니다. 예를 들어 String Interpolation에서 참조된 변수를 찾으려면, 기존 컴파일러는 두 번의 Map 탐색을 진행해야 합니다. 새로운 K2 컴파일러는, 그 대신, FIR의 트리 구조에 의존합니다. 규모가 큰 HashTable 자료구조에서 두 번 탐색을 진행하기보다, 트리 노드의 멤버 값에 바로 접근하는 게 (당연히) 훨씬 빠르죠.
Call Resolution과 Type Inference를 마쳤으며, 의미적(Semantic)으로 어떠한 오류도 보고되지 않은 나무(PSI Tree)가 우리 앞에 있습니다. 이제 Semantic Analyzer가 알아낸 모든 정보를 백엔드로 보낼 시간입니다. 여기서, 우리는 어떤 형태로 보내야 가장 효율적일지 생각해 보아야 하지요. 이에 대한 Kotlin 생태계의 첫 대답은 BindingContext 이었습니다. 하지만, 첫 응답과 동시에, BindingContext 는 Kotlin 컴파일러가 상환해야 할 첫 번째 기술적 부채가 됩니다. 그 이유를 살펴보기 위해, 조금 깊이 들어가, 이 Table이 어떻게 구현되었는지와 함께 그것의 치명적인 단점을 다루어 보겠습니다.
먼저 (구체적인 형태가 아직 드러나지 않은) Interface를 살펴보도록 하죠. 이번에도 JetBrains의 Kotlin Repo입니다.
compiler/frontend/src/org/jetbrains/kotlin/resolve/BindingContext.javapublic interface BindingContext { BindingContext EMPTY = new BindingContext() { ... @Override public <K, V> V get(ReadOnlySlice<K,V> slice, K key) { return null; } ... }; ... WritableSlice<KtTypeReference, KotlinType> TYPE = Slices.createSimpleSlice(); WritableSlice<PsiElement, SimpleFunctionDescriptor> FUNCTION = Slices.createSimpleSlice(); WritableSlice<KtParameter, VariableDescriptor> VALUE_PARAMETER = Slices.createSimpleSlice(); WritableSlice<KtReferenceExpression, DeclarationDescriptor> REFERENCE_TARGET = new BasicWritableSlice<>(DO_NOTHING); ... }
BindingContext는 굉장히 독특한 구조를 가지고 있습니다. 전체적인 형태는 Map이나, Key를 특이한 방식으로 관리합니다.
Slice라는 자료구조와 PSI Tree의 Element를 2-Tuple(Kotlin에서는Pair로 구현됩니다) 로 묶어 관리하죠. BindingContext에서 사용되는 Slice는 모두 BindingContext 인터페이스 안에 선언되어 있습니다.TYPE은 그 중 하나입니다.

compiler/frontend/src/org/jetbrains/kotlin/resolve/CompositeBindingContext.ktclass CompositeBindingContext private constructor( private val delegates: LinkedHashSet<BindingContext> ) : BindingContext { override fun getType(expression: KtExpreesion): KotlinType? { return delegates.asSequence().map{ it.getType(expression) } .firstOrNull{ it != null } } companion object { fun create(delegates: List<BindingContext>): BindingContext { if (delegates.isEmpty()) return BindingContext.EMPTY val delegateSet = LinkedHashSet(delegates) if (delegateSet.size == 1) return delegates.first() return CompositeBindingContext(delegateSet) } } ... override fun <K, V> get(slice: ReadOnlySlice<K,V>?, key: K?): V? { return delegates.asSequence().map { it[slice, key] } .firstOrNull { it != null } } ... }
Backend with IR
Front end
The front end analyzes the source code to build an internal representation of the program, called the intermediate representation (IR). It also manages the symbol table, a data structure mapping each symbol in the source code to associated information such as location, type and scope.
(컴파일러) 프론트엔드는 소스 코드를 분석해 (컴파일러) 내부에서 사용되는 표현식을 만듭니다. 이를 Intermediate Representation, 줄여서 IR이라고 부르죠. 프론트엔드는 (Source Code 내의 Symbol들을 메모리 주소, 타입, 스코프와 매핑시키는 자료구조인) Symbol Table도 관리합니다.
프론트엔드는 기본적으로 IR을 만드는 임무를 맡습니다. ‘원론적’으로는 그렇습니다. 하지만 (Improvements in K2에서 다룰 Frontend IR에 한해) v2.0.0 이전의 Kotlin은 예외였지요. Background 블록 에서는 프론트엔드가 IR을 생성하는 일이 마치 흔하지 않은 것처럼 서술해 두었지만, 사실은 IR을 생성하지 않는 경우가 더 희소합니다. 이런 예외적인 상황은 Kotlin과 떼려야 뗄 수 없는 특성인 Multi-Platform 지향성과 관련이 있습니다. 분명 IR을 생성하는 것이 더 빠른 컴파일러를 위해 나은 선택임이 분명함에도, 그러한 특성을 생태계에 빠르게 입혀내기 위해 선택한 일종의 기술 부채(Technical Debt) 이죠. (사실상 Multi-platform의 모든 짐을 떠안게 된) Kotlin 컴파일러 백엔드에 IR이 도입된 과정을 살펴보며, 초기의 Kotlin이 왜 IR을 포기하고 시작했는지 알아보고, 컴파일러가 나아가야만 했던 방향에 대한 힌트를 얻어 볼게요.
|
|
백엔드에 별도의 변환 및 최적화(optimization) 없이 PSI Tree와 BindingContext (일종의 Symbol Table)을 그대로 넘겨주는 모습입니다. 초기 Kotlin 생태계의 설계자들에게, 두 백엔드를 묶어볼 무언가를 고안해 내기란 시간이 촉박했을 겁니다. 단순하게 생각해 봐도, JVM (Java Virtual Machine)이 생성하는 바이트코드와 다르게, JavaScript는 거의 Kotlin과 비슷한 정도의 고수준(High-level) 언어이기 때문이죠. Kotlin은 빠르게 성장하기 위해 처음에는 쉬운 길을 택했습니다.
|
|
|
그런데 Native Backend가 등장합니다. Kotlin이라는 언어를 컴퓨터가 이해할 수 있는 형식으로 창출해내기 위해, 어떠한 경유지도 거치지 않을 수 있는 유일한 방법 말입니다. 이 방법을 왜 고안해 내야만 했을까요. (ES라는 타겟이 있음에도 불구하고,) Kotlin은 오랜 시간 동안 Java와의 상호 운용성(Interoperability)으로만 주목받아 왔습니다. 물론 Java를 장기적으로 대체하는 언어가 되는 것도 중요하지만, 그에 앞서 모든 플랫폼에서 사용되는 범용 언어로 성장하는 게 우선이었죠. macOS, iOS, 임베디드 생태계에서 뿌리내리기 위해서는 (JIT를 장착했음에도) 느리고 무거운 JVM을 계속 어깨에 이고 갈 순 없었습니다. 그래서 LLVM을 도입합니다. Instruction Set Architecture 너머 바이너리로 가장 빨리 도달할 수 있는 티켓, 그 비싼 티켓의 값을 Kotlin 생태계는 Backend IR을 구성하며 치러 내었습니다. 처음으로 Kotlin 컴파일러의 기술 부채를 상환한 셈이죠.
|
Kotlin/Native is a frontend of LLVM Infrastructure
Overview
 The LLVM Project is a collection of modular and reusable compiler and toolchain technologies. Despite its name, LLVM has little to do with traditional virtual machines.
The LLVM Project is a collection of modular and reusable compiler and toolchain technologies. Despite its name, LLVM has little to do with traditional virtual machines.
LLVM 프로젝트는 모듈화되어 재사용 가능한 컴파일러와 툴체인 기슬의 집합입니다. 이름에서 나타나는 것과 달리 LLVM은 고전적인 의미의 가상 머신과는 거의 관련이 없습니다.LLVM을 간단하게 이야기하면, 모듈화(Modularize)된 컴파일러입니다. 특히 프론트엔드를 탈부착하는 데 용이하며, 다양한 프로그래밍 언어(C, C++, Fortran, Haskell, Java Bytecode, Julia, Objective C, Ruby, Rust, Scala, Swift 등등)의 컴파일러 백엔드 역할을 수행합니다.
Overview에 그려진 LLVM의 구조에서, 가장 중요한 부분은 IR (중간 표현) 그리고 Optimization (최적화) 입니다. IR은 고급 언어의 추상적인 특성을 유지하면서도, ISA(Instruction Set Architecture) 코드로 이어지는 징검다리를 놓는 역할을 수행하죠. LLVM에서의 최적화는 1차적으로 코드에 대한 분석을 진행하고, 필요에 따라 연산 순서를 변경하며, 불필요한 코드를 제거하는 등의 작업을 일컫는 말입니다.
C,C++,Objective-C의 경우에는, Clang이라는 프론트엔드를 사용하여 Raw한 형태의 IR를 생성하고, 이를 LLVM에서 Machine Code로 변환할 수 있습니다. (Kotlin과 함께) 비교적 신생 언어 축에 속하는Swift의 컴파일러 프론트엔드는 아예 LLVM이 인식할 수 있는 IR을 생성하는 데 주안을 두고 설계되었습니다. 하지만 이미 JVM과 JS Backend를 지니고 있던 Kotlin의 경우에는 조금 다른 접근이 필요했습니다.

v2.0 이전의 Kotlin 컴파일러 프론트엔드는 PSI Tree를 생성하는 Parser 그리고 BindingContext를 덧붙이는 Semantic Analyzer로 이루어져 있습니다. 하지만 LLVM의 Backend를 활용하려면 Raw한 형태의 IR이라도 생성해야만 했죠. 앞에서 다루었던
C,C++,Objective-C, 그리고Swift를 포함한 대부분의 언어는, 일반적으로 IR 생성을 프론트엔드에서 도맡아 합니다. 그러나 Kotlin 생태계는 (시간이 오래 소요될 게 뻔한) IR을 생산하는 프론트엔드를 개발하기보다, 먼저 네이티브 백엔드에서 Raw한 IR을 생성하는 역할을 부여하기로 선택합니다. 그렇게 조금은 이상하게도, Raw IR Generator는 Kotlin 컴파일러에서는 백엔드에 속하고 LLVM의 전체적인 구조에서는 프론트엔드에 속하게 됩니다.
|
|
세 백엔드의 IR 형태가 정말 다른 것인가?
그렇다면 이 다이어그램은 무엇을 표현하는 거지?
그저 IR을 생성했다는 것에 주안점을 둔 것인가?
|
Improvements in K2
Backend IR로는 부족하다. 더 빠른 컴파일을 위해서는 무엇이 필요할까?
K2 등반만큼 어려운 길.
Why Rewrite the Compiler
Kotlin 컴파일러의 1.0 버전은 빠른 속도를 첫 번째 목표로 두고 만들어지지 않았습니다. 그 대신, 빠르게 컴파일러의 모습을 갖추는 것이 최우선이었죠. 세상에 막 첫 발을 딛은 신생 언어에게, 성능의 향상은 부차적인 요소일 수 밖에 없습니다. 하루라도 빨리 안정화 버전(Stable Version)을 내보이는 게 더 중요하니까요. 하지만 생태계가 성장하면서 구성원의 요구사항은 점차 많아집니다. Kotlin과 같은 Multi-Target 언어에게 안정화 다음으로 가장 시급하게 해결해야 할 과제는 바로 속도였죠. 빠른 컴파일 이외에도 메모리의 효율적인 사용, 멀티 스레딩, 컴파일러 구조의 단순화, 멀티플랫폼으로의 원활한 지원, 그리고 새로운 문법적 설탕을 도입하는 데 있어, 컴파일러를 다시 작성하는 건 선택이 아닌 필수였습니다. 특히 새로운 프론트엔드를 작성하는 일 말이죠.
Transparent Box : Raw FIR Builder
- 새로운 Frontend에 대한 전체적인 로드맵 가져오기
- Raw FIR에 대한 내용 가져오기
- Desugaring Phase에 대한 내용 가져오기
Transparent Box : Analyzer
- New Analyzer에 대한 내용 간추려 보기
- Why K2 frontend is faster : 3가지 이유 알기 쉽게 정리해 보기
Jump Reduction
Smart Cast
New Features of 2.0
사실상 컨퍼런스 키노트의 메인 챕터입니다. 앞으로의 Kotlin 코드베이스가 어떤 방향으로 돛을 돌릴 지 짐작할 수 있는 중요한 단서이기 때문이죠. 여기서는 조금 호흡을 길게 가져가도록 하겠습니다. 숨 깊게 들이쉬시고, static 키워드가 먼저 여러분을 찾아갑니다.
Static Extensions
우리가 그 실체에 다가갈 수 없는, Third-Party Class를 하나 가정해봅시다. 완전히 닫혀 있지만, 다행히도 우리는 *Companion Object가 그곳에 존재한다는 사실 정도는 알고 있습니다. 불행 중 다행입니다. 막 ‘정적인 확장 함수(Static Extension)를 작성하려던’ 참이었거든요.
class QuotesTable(val quotes: List<Quote>) {
companion object {
}
}
-----
fun <T> QuotesTable.Companion.OpenFilteredBy(quotePropety: T) {
println("Hello, Static Extensions!")
}
fun main() {
QuotesTable.OpenFilteredBy("Ian McEwan")
}
* Companion Object
If you need to write a function that can be called without having a class instance but that needs access to the internals of a class (such as a factory method), you can write it as a member of an object declaration inside that class.
Class의 인스턴스를 생성하지 않고 호출되는 함수를 작성하고 싶을 때, 그러나 그것을 Class의 내부 요소에 접근하도록 하고 싶을 때, 구현하고 싶은 함수를 Class 안에 Object를 선언한 형태(
companion object)의 멤버로 작성하면 됩니다. 출처: Classes | Kotlin Documentation
그런데 이러한 ‘닫힌 클래스’에 Companion Object가 존재하지 않는다면 어떻게 될까요?
삐빅! 빨간불입니다.
아쉽게도 우리는 그러한 시도조차 하지 못하게 됩니다. Kotlin 컴파일러는 Unresolved Reference 에러를 내며 이를 거부합니다. 1.9.20까지의 Kotlin에서는, 일단은, 그렇습니다.
Kotlin은 Java와 달리(그리고 다른 많은 언어들과 달리), 명시적으로 static이라는 키워드를 사용하지 않습니다. 대신 최상위 함수(Top-level Function), 동반 객체(companion object), 싱글톤 패턴(Singleton pattern) 지원 등으로 그의 역할을 효과적으로 대체한 것이죠.
그럼에도, Kotlin 생태계에서 Class의 정적인 멤버(Static Member), 정적인 확장(Static Extension), 정적인 객체(Static Object)에 대한 논의는 꾸준히 이루어져 왔습니다. Kotlin 생태계에 대한 여러 고민들을 엿볼 수 있는 KEEP - Kotlin Evolution and Enhancement Process에서 구체적인 배경을 조금 더 살펴보도록 하죠. (Introduction 내용을 본문에 실었습니다.)
1. Enable static extensions of 3rd party classes, which is the top most voted feature in Kotlin.=> 서드파티 클래스에 대한 정적 확장을 허용합니다. 이는 Kotlin 개발자들에 의해 가장 많이 요구된 기능입니다.
2. Provide a lighter-weight mechanism for defining static members that do not access instance variable as an alternative to companion objects in many use-cases.=> Companion object에 대한 대안으로, (인스턴스를 생성하지 않고) 정적 멤버를 정의하는 데 더욱 가벼운 매커니즘을 제공합니다.
3. Simplify interoperability with JVM statics that Kotlin compiler has to support anyway — more concise and clear usage of Java frameworks that rely on statics, easier Java to Kotlin migration.=> (미우던 고우던 Kotlin 컴파일러가 지원해야만 하는) JVM
static과의 상호 운용을 단순화합니다. 이는 (Kotlin에서)static에 의존하는 Java 프레임워크의 간결하고 명확한 사용을 보장하며, Java로부터의 마이그레이션을 더욱 쉽게 만듭니다.
컨퍼런스에서 언급한Companion키워드가static이 되는 마법을 적용해 보면,fun <T> QuotesTable.static.OpenFilteredBy(quotePropety: T) { println("Hello, Static Extensions!") }
QuotesTable.static이 Receiver Type이 되면서 모든 문제가 해결된 것처럼 보입니다.
이렇게만 보면, static 키워드를 도입하는 것이 만사형통의 지름길로 보일 수 있겠지만, 속을 뜯어보면 그렇지만은 않습니다. 태초에 Kotlin은 명시적으로라도 static을 사용하지 않기로 약속한 언어인데, 이미 구축된 생태계를 뜯어고치려면 얼마나 많은 논의가 필요할까요? 수많은 의제를 담은 이 커다란 논쟁에서 두 줄기만 짧게 가지고 왔습니다.
Issue 1: Section syntax or Modifier Syntax
static section |
static modifier |
|---|---|
|
|
아직 static 멤버와 클래스, 인터페이스를 선언하는 방법마저 확실하지 않은 상황입니다. (키노트에서도 이를 어떻게 다룰 것인지 명확한 언급이 없었습니다. static 키워드를 정적인 확장 함수를 지원하는 데만 국소적으로 사용하지는 않을 것이니, 이는 Kotlin 생태계에 있어 확고한 분기점이 될 것임은 자명합니다.)
KEEP 문서의 해당 섹션을 간추려 보면, (불행인지 다행인지는 알 수 없지만) Section Syntax와 Modifier Syntax를 도입하는 데 있어 각각의 장단점은 명확합니다.
Section over Modifier
- Companion object로부터의 마이그레이션이 쉬울 것입니다. (모든 정적 멤버를 일정한 공간에 묶어 둔다는 점에서 개념적으로 유사합니다.)
fun SomeClass.static.ext()이 보다 직관적인 구문(mnemonic expression)이 됩니다. (Static section의 확장이라는 것이 명확해집니다.)
Modifier over Section
- 다른 언어에서
static을 사용하는 방식과 유사합니다.- 간헐적으로 사용하는
static선언에 더욱 간결한 방식을 제공합니다.
We'll have to make once choice of syntax and accept all its disadvantages for the sake of having a consistent syntax across Kotlin codebases.
---
그리고 두 옵션 모두가 사용되는 일은 없을 것입니다.
(전략) 둘 중 하나만을 택할 것이며, 그 선택에 뒤따를 모든 부정적인 결과를 감수하고 Kotlin 코드베이스의 안정된 문법 환경을 지켜낼 것입니다.
장단점이 명확한 두 가지 방식 중, 반드시 하나만을 선택해야 한다라… Kotlin을 손에 든 만국의 개발자 여러분, 우리에게 아직은 인내심이 더 필요할 듯 합니다.
Kotlin의 static 키워드 도입이 빠르게 이루어지기에는 요원한 이유를 조금 더 살펴보겠습니다. 두 번째 이슈입니다.
Issue 2: Static soft keyword ambiguity
1️⃣
class Example { class static { // a valid declaration of a nested class fun innerFunc() { this.ext() } } private val ex = static() fun exFunc() { ex.innerFunc() } }
2️⃣
fun Example.static.ext() { // Currently parsed as extension on `Example.static` class. println("static is soft keyword") } fun main() { val example = Example() example.exFunc() }이 스파게티 코드는 놀랍게도 정상적으로 컴파일됩니다…
2️⃣에서는 분명 우리가 Example 클래스의 정적인 확장 함수를 작성한 것처럼 보이지만, 실상은 1️⃣과 같이 사용되는, 그냥 nested class(Example.static)의 인스턴스를 Receiver로 하는, 일반적인 확장 함수를 작성한 것입니다.
이게 다 static이 Static Extension의 기획에서 Soft Keyword로 작동하기 때문에 발생한 참사입니다. KEEP 문서에서도 일종의 ‘Deprecation Cycle’이 필요하다며 이러한 모호함을 온전히 제거하는 데 시간이 어느 정도 소요될 것임을 암시하고 있습니다.
The detailed design on how to deal with this ambiguity is TBD. Initially, the compiler will have to parse this code as it was parsed before, which will complicate the implementation ofExample.staticconstruct as it'll require the extra resolution step. We'll need to develop some kind of deprecation cycle to remove this ambiguity. The reasonable approach to such deprecation is to deprecate all nested and inner classes, interfaces, and objects with the namestatic.
이 모호함에 대해 생태계 차원에서 어떻게 접근할지는 아직 미지수입니다. 일단 컴파일러는 기존의 방식대로 코드를 분석할 것이며, 이는
Example.static구조를 작성하는 데 복잡함을 가중시킬 것입니다. (이게 클래스 이름인지 예약어인지 구분하기 위해) 추가적인 처리가 필요할 테니 말이죠. 그래서 이러한 모호함을 제거하기 위해, 우리는 일종의 Deprecation Cycle을 개발해야 합니다. 이에 대한 합리적인 접근은static의 이름을 가진 모든 중첩 및 내부 클래스, 인터페이스, 그리고 객체를 Deprecate하는 것입니다.
위 내용들을 종합해 보았을 때, “서드파티 클래스에 대한 정적 확장” 이라는 이상보다, 더 나아가, static이라는 키워드를 통해 코드베이스를 어떻게 재편할 것인지에 대한 고민이 아직은 더 필요해 보입니다. Kotlin은 상대적으로 어린 언어이며, 땜질보다는 기둥부터 단단하게, 프로그래밍 언어의 백년지계(百年之計)는 천천히 닦아나가야 하니까요. (‘땜질’이라는 표현에서 어떤 언어가 생각났다면, 뇌리를 스쳐간 그것이 바로 정답입니다.)
Collection Literals
val list1 = listOf(0, 1, 2, 3)
Kotlin에서 Collection을 선언(Declare)하는 방법은 독특합니다. JavaScript, Python, Swift, Go와 같이 현대의 개발자들이 선호하는 언어들과도 결이 크게 다른 편이지요.
흔히 List(혹은 Array)를 선언한다 하면, Element들을 [](Array Literal)로 감싼 뒤 특정 변수에 대입하는 방식이 일반적입니다.
언어에 따라 Literal의 종류는 달라질 수 있겠지만, Kotlin처럼 Collection의 선언을 함수로만 강제하는 경우는 드문 편입니다.
이는 Collection Literal을 지원하지 않는 Java와의 상호 운용성이 간결함의 발목을 잡은 경우입니다. Kotlin 생태계의 Collection Literal 도입에 대한 Jetbrains YouTrack의 발제를 보면 그 이유가 조금 더 또렷해지는데요. 모두 literal을 도입하는 데 있어 합리적인 동인(動因)이지만, ‘비효율적(Inefficent)‘이라는 단어가 포함된 네 번째 요소가 눈에 띱니다.
- Collection literals are concise, which is important in data-heavy applications (esp. data-science).
=> Collection Literal이 더 간결한 문법을 제공합니다. 이는 무거운 데이터를 다루는 애플리케이션에서 특히 중요합니다.
- Collection literals are more regular. Without collection literals you’ll have to remember, by heart, a separate function to create each type of collection.
listOf,mapOf,setOf,intArrayOf, etc -> there’s a lot of collection construction functions to navigate.=> Collection Literal이 더 널리 사용됩니다. Collection Literal이 없다면 각 컬렉션을 생성하는 데 필요한 함수를 외우고 있어야 합니다.
- Collection literals can play better with type-inference.
=> Collection Literal은 타입 추론과 손발이 더 잘 맞습니다.
- Collection literals give Kotlin a chance to address the long-standing design problem that the general creation of collections is currently inefficient in Kotlin due to the underlying use of varargs.
=> Collection Literal은 Kotlin의 해묵은 디자인 문제인 varargs 사용으로 인한 컬렉션 생성의 비효율을 해결할 수 있는 기회를 줍니다.
Kotlin에서 컬렉션 생성을 도맡는 함수들의 Signature(Function Signature)를 보면, 공통된 부분이 존재하는데요. 바로 vararg라는 Modifier입니다. vararg는 Kotlin에서 함수를 선언할 때, 고정되어 있지 않은 수의 동일 타입 인자를 전달해야 하는 경우(To declare a parameter that accepts a variable number of arguments of the same type) 사용합니다.
🗃️ Github Repo: JetBrains/kotlin -
kotlin/libraries/stdlib/src/kotlin/collections/Collections.kt
listOf()와 비슷하게, setOf()도, mapOf()도 vararg 를 이용해 주어진 요소들을 뭉쳐내어 컬렉션으로 리턴하는 함수들입니다. 겉으로만 보면, Java와의 상호 운용성도 만족하고 가변적인 크기의 컬렉션을 선언(Declare)하는 데 최적의 선택지인 듯 하지만, Discussion에서 Kotlin이라는 언어 디자인의 해묵은 문제(long-standing problem)이라 언급한 데에는 두 가지 이유가 있습니다. (이 문제에 대해서는 StackOverflow: Java’s varargs performance를 참고했습니다.)
1. vararg는 타입이 아니라 문법적 설탕(Syntatic Sugar)입니다.
varargs는 기본적으로 메서드입니다. 동일한 타입을 가진 여러 인자(argument)를 받아, 그 개수를 파악한 뒤, 이를 Array로 변환하여 리턴하는 함수이지요. 이러한 사실을 알려주는 Indicator를 약간의 Deep-Dive를 통해 파악할 수 있습니다. 다음 Kotlin 코드를 JVM(Java Virtual Machine) 위에서 컴파일한다 가정해 봅시다. 간단한 함수를 Kotlin Compiler를 통해 Java ByteCode로 변환[7]해 보면,
Kotlin의 vararg Modifier는 Java의 Varargs로 치환됩니다. 또한 ACC_VARARGS 플래그는 sum1() 함수에 가변 개수의 파라미터를 전달됨을 확인합니다. 하지만 이 부분들만 체크해서는 Varargs가 문법적 설탕임을 단정짓기 어렵습니다. 결정적인 증거는 바로 descriptor라는 부분에 존재합니다.
Java ByteCode를 이루는 Instruction 중, descriptor는 메서드의 인자(Argument)와 Return Type을 나타냅니다. 소괄호 안쪽을 보면 인자의 타입과 수를 알 수 있는데요. 여기서는 [I가 이에 해당됩니다.

Type Descriptor가[로 시작하면, 이는 배열(Array)을 의미하는 것입니다.
그러니[I는 Integer 타입의 요소를 가진 Array라는 의미입니다.
결국, Kotlin에서의vararg ns: Int는 Java에서의int...와 동일하게 취급되고, JVM에서는 이를int[]와 동일하게 취급한다는 결론에 이르게 됩니다.
이 지점에서 발생하는 첫 번째 문제는, 함수의 인자(argument) 수가 불변할 때보다 varargs의 퍼포먼스가 현저히 떨어진다는 것입니다. 해당 문제에 관한 Accepted Answer를 보면, 이에 대한 이론적 근거를 쉽게 찾을 수 있습니다. 그리고 느린 속도를 유인하는 아래의 사실은 곧바로 두 번째 문제와 직결됩니다.
Static list of arguments is quite different from an array. When you pass them that way, compiler reserves space for the references and populates them when the method is called.Varargs is an equivalent of array. To call such a method, it’s necessary to create and populate array at run time.
(메서드에) 정해진 수의 인자들을 전달하는 건 일반적인 배열(Array)을 전달하는 것과 크게 다릅니다. 전자의 경우에는 (Compile Time에) Compiler가 (Method Signature에 있는 만큼의) 메모리를 확보하고 메서드가 사용될(called) 시 그 인자들을 활용합니다. Varargs는 Array와 동일하게 작동합니다. varargs를 사용하면, Compiler는 Runtime에 메모리 확보 및 Array 생성까지 진행하게 됩니다.
2. vararg는 Kotlin의 안정성을 해칩니다.
본문 초반에 인용했던 문장을 다시 들고 왔습니다. Kotlin에서 정적 바인딩을 선호한다는 것을 풀어 이야기할 때, 앞에서는 클래스와 메서드에 대해서만 언급하였지만, 바인딩(Binding)은 사실 개념적 폭이 더 넓은 단어입니다. 메서드 ’호출과 본문의 연결(Association of method call to the method body)’이라고 개념적인 너비를 좁혀서 서술할 수도 있지만, 특정 데이터를 일정한 메모리 주소에 묶어두는 것이라고도 설명할 수 있습니다.
| 코틀린은 동적 바인딩보다 정적 바인딩을 더 선호한다 |
코틀린은 타입 안전한, 합성적인 코딩 스타일을 장려한다. 확장 함수는 정적으로 바인딩된다.
기본적으로 클래스는 확장될 수 없고, 메서드는 다형적이지 않다.
여러분은 명시적으로 다형성과 상속을 활성화해야 한다.
덩컨 맥그레거, 냇 프라이스, 오현석 역,『자바에서 코틀린으로(Java to Kotlin: A Refactoring Guidebook)』(2021), 한빛미디어, 2022, p.30.
정적인(Static) 바인딩은 컴파일 타임(Compile Time)에 이루어지는 바인딩이며, 동적인(Dynamic) 바인딩은 런타임(Rumtime)에 이루어지는 바인딩입니다. Kotlin의 언어 디자인은 컴파일 타임에 이루어지는 바인딩을 지향합니다. 객체지향 프로그래밍(OOP), 확장 함수(Extended Function)의 바인딩 방식은 이러한 경향성에서 기인할 뿐이지요. 이러한 디자인의 방향성에서, varargs라는 설탕의 탈을 쓴 ‘Dynamic Array’는 옥의 티라고 할 수 있겠습니다. 결국 Collection Literal의 도입은, 기타 요소에 의존하지 않는, Kotlin Collections의 정적인 바인딩을 향한 여정과 궤를 같이합니다. Collection Literals이 충족해야 하는 조건을 보면 이와 같은 의도를 더욱 명확하게 읽어낼 수 있습니다.
Requirements
6. Construction of collection literals shall be efficient by design, without needing to have special optimization in compiler. The underlying mechanism shall not rely onvarargs,Pairs, or other wrappers.
Collection Literal의 구현은 컴파일러 차원의 특정한 최적화를 필요로 하지 않고, 오로지 언어 디자인 차원에서만 다루어질 것입니다. 내부 메커니즘은 (지금처럼) varargs나 Pair(K,V) 등의 wrapper에 의존하지 않을 것입니다.
Flexible한 Collection Literal을 구현하는 데에 있어, 산적한 과제들 중 하나를 소개하겠습니다. 사실상 위에서 소개한 여섯 번째 조건에 이어지는 이야기인데요. (아래는 YouTrack Issue의 발제 중 Concerns를 번역하고 간추려 정리한 것입니다.)
Concerns
여기에, 데이터 클래스 하나와 함수 하나가 놓여있습니다.

drawLine이라는 API는, 지금까지의 Kotlin에서는, 이렇게 사용됩니다.

(코드에 이런 표현을 덧불이는 게 적절한지의 여부에 대한 판단을 뒤로 제쳐두고,) 이 코드는 장황합니다. 지금의 Kotlin에서 이 장황함을 해결할 수 있는 방법은, 원시 타입(Primitive Type)으로 인자(Argument)를 대체하는 Overloading 뿐이지만, 이는 API의 타입 안정성을 해칩니다. 그리고 새로운 함수를 구현해야 할 만큼의 보상, 그만큼의 간결함도 주어지지 않지요.

만약 우리의 손에 “유연한 형태의 Collection Literal”이 들려 있다면,
Point라는 Class를 Collection으로 가정하고 싶은 강렬한 유혹에 빠질 것입니다.[]라는 가상의 Collection Builder를 통해 새로이 함수를 호출해 보면, 다음과 같은 형태를 띱니다.

객체에 Literal을 씌워 관리하는 대표적인 언어로 JavaScript가 있습니다. 이를 Object Literal 이라고 일컫는데요. JavaScript에서는 {}를 사용하는데, 아직 Kotlin에서는 Data Class의 인스턴스를 Literal을 씌워 관리하는 규칙이 정해지지 않았습니다.
하나의 이슈가 가진 수많은 가지들을 여기서 다 다루지는 못하겠지만, 단 하나 분명한 건 간결함을 향한 Kotlin의 여정에는 아직 수많은 과제가 남아 있다는 사실입니다. 근본적인 Language Design의 재구성을 감내해야만 하는, 올해의 키노트에서 다룬 이슈는 하나 더 있습니다. 바로 Name-based Destructuring입니다.
Name-based destructuring
우리는 필요에 따라 데이터를 결합하거나 해체합니다. 결합이 필요할 때는, 다양한 자료구조(Data Structure)를 통해 구조화(Structuring)시키고, 필요한 데이터를 그 속에서 탐색하거나 아예 분리시키는 일에 익숙합니다. Kotlin Standard Library에서는 우리가 많이 사용하는 자료구조를 Collection 인터페이스와 그 하위 Class들로 정리해 두었죠. (참고로, Map 인터페이스는 Collection 인터페이스와는 독립적으로 존재합니다. )

⬆️ Kotlin Documentation | Collections overview의 내용을 재구성한 다이어그램.
Collection Interface들 사이의 상속 관계를 나타내었습니다.
List라는 Collection의 뿌리를 파고 들어가보면(격식을 갖추면, 인터페이스의 조상님을 찾아나서는 일이라고 할 수 있겠네요), Iterable이라는 인터페이스가 보입니다. 이 인터페이스를 상속받는 클래스들은 공통된 특성을 가지고 있습니다. Iterable - Kotlin Programming Language의 내용을 가져와 보면,
interface Iterable<out T>
Classes that inherit from this interface can be represented as a sequence of elements that can be iterated over. 이 인터페이스를 상속받는 클래스는 순회의 대상이 되는(반복 가능한) 특정한 요소의 나열을 표현합니다.
즉, 다른 언어에서의 경우와 마찬가지로, (Keynote에서의 말을 빌려) Collection은 기본적으로 순서-지향적(positional) 입니다. 그런데 Kotlin은 데이터들을 결합하는 방법으로, Collection을 제외하고, 조금은 특별한 형태의 클래스를 사용합니다. 앞에서 간결함(Kotlin is Concise)에 대해 설명하며 소개했던 data class의 존재입니다.
data class Person( val firstName: String, val lastName: String )이 친구는 구성 요소의 순서와 전혀 상관 없어 보입니다. (우리가 사용하는 ‘언어’ 그리고 살아가는 문화권에 따라서 그 순서가 달라진다는 사실은 논외로 합시다.)
data class는 name-based 입니다. 이 곳에 결합된 데이터들이 모두 자신만의 특성을 가진다는 점에서 말이죠. Collection과는, 그것이 비슷한 속성의 여러 요소를 한 데 모아둔 형태라는 점에서, 방향이 가장 크게 갈립니다. 주로 데이터베이스나 .json 형태의 파일을 시각화(Visualize)하는 데 사용하는 data class는 그 존재에 있어, 어떤 속성을 가지고 있다는 사실이 중요한 것이지, 그 속성이 배치된 순서와는 하등 관계도 없고 그러한 목적을 위해 만들어진 것도 아니기 때문입니다.
그런데 data class의 인스턴스를 구조 분해(Destructuring)하는 경우에는 어떨까요?
당연히, 구성 요소를 합치는 데에 순서가 중요하지 않다고 했는데, 분해했을 때도 마찬가지 아닐까요?
/**person is an instance of data class named Person*/ val (firstName, lastName) = person놀랍게도(?) 아니었습니다.
위 문법은 data class의 인스턴스가 가진 정보를 분해해 두 변수에 저장하는 경우 사용하는데요. 아직까지는, 이 분해 과정이 철저하게 positional하다는 것이 문제입니다. 키노트에서 “Kotlin 2.0의 첫 번째 릴리즈에서는 볼 수 없겠지만, 분명 고칠 것(“We are going to fix it”)” 이라 공언했으니, 생태계에서 과연 이 문제를 어떻게 해결할 지 조금 더 지켜보도록 하지요.
Context Receivers
Explicit fields
명백한 ‘Field’라, 명백한 운명(Manifest Destiny)도 아니고 도대체 무슨 의미일까요?
먼저, 기존에는 Kotlin에 ‘명시적인’ field가 존재하지 않았으므로, 새로운 기능을 탐구함에 앞서 이 키워드가 ‘뒤에서’ 사용되는 방식을 먼저 살펴보겠습니다.
(이 글에서 자주 등장하는 언어인) Java에서 필드(Field) 라 하면, 클래스 안에 정의되는 변수(A variable declared inside a class) 를 의미합니다. 그리고 (JavaBeans의 작성 원칙을 충실히 따른다는 전제 하에) static이 아닌, 인스턴스 필드의 접근 제한자(Access Modifier)는 private으로 설정되어야 하지요. 그리고 Java에서는 getter와 setter(다른 말로는 Accessor와 Mutator 메서드)를 개발자가 임의로 작성함으로써, Field와 함께 하나의 Property를 구성합니다.
Property (programming)

A special sort of class member, intermediate in functionality between a field (or data member) and a method.
Class 멤버의 특수한 형태로, 필드와 메서드 영역의 중간에서 특수한 기능을 제공합니다.
(여기서 특수한 기능이라 함은, 데이터를 캡슐화(Encapsulate)하고, 해당 데이터에 대한 접근 권한을 getter와 setter 메서드로 통제하는 것입니다.)
명시적으로 하나의 field에 대한 두 개의 메서드를 구현해야만 Property를 구성할 수 있는 Java와는 달리, Kotlin은 (Concise에서 언급했듯이) Field에 대한 선언이 곧 Property에 대한 선언입니다. 이것이 Kotlin의 Field가 ‘명시’적이지 않은 첫 번째 이유입니다. Kotlin에서는 순수한 의미의 Field를 선언할 수 없기 때문이지요. 그렇다면 명시적이지 않은 필드(이를 Backing Field라고 합니다)는 어떤 경우에 사용할까요?
위 코드는 Kotlin 클래스 내에서 var 키워드로 Property를 선언하는 경우 자동으로 생성되는 Accessor와 Mutator 메서드를 명시적으로 선언한 것입니다. 이를 접근자 메서드의 "Default Implementation" 이라고 합니다.
이는 Java에서 JavaBeans에 따라 Property를 구성하는 방식과 동일합니다.
위의 예시가 보여주듯, ”Property의 값을 저장하는 역할로서, 독립적인 형태로 전면에 나서지 않고, 온전히 그것 뒤에 숨어있기 때문”에, Kotlin에서의 field는 Backing Field라는 별칭을 얻게 된 것입니다. 그러나, Property를 생성할 때마다 Backing Field가 저절로 만들어지는 것은 아닙니다. Kotlin의 Property에 관한 공식 문서에 따르면, 다음과 같은 경우에만 생성됩니다.
A backing field will be generated for a property
if it uses the default implementation of at least one of the accessors,
or if a custom accessor references it through the field identifier.
Backing Field는 다음과 같은 경우에 생성됩니다.
- 최소 하나의 접근자 메서드에서 “Default Implementation”을 사용한 경우.
- 또는 커스텀 접근자가
field라는 예약어로 이를 참조한 경우.
그렇다면, field가 명시적으로 표현되어야 하는 경우에는 무엇이 있을까요?
이는 객체지향의 네 가지 기둥(Pillars) 중 하나라 할 수 있는 캡슐화(Encapsulation) 와 깊은 관련이 있습니다.
사실 Kotlin Property의 기능만으로는 캡슐화된 필드(field)를 구현하기 어렵습니다. 특히 Data Structure를 취급하는 데 있어 더욱 그러한데요. 그 이유는 영문 위키피디아에서 언급한 캡슐화의 두 가지 조건을 살펴보면 찾을 수 있습니다.
- A language mechanism for restricting direct access to some of the object’s components
- A language construct that facilitates the bundling of data with methods(or other functions) operating on those data
- 특정 객체의 구성 요소에 대한 직접적인 접근을 막는 매커니즘.
- 데이터와 (그 데이터를 활용하는) 메서드의 묶음을 용이하게 하는 구조.
Kotlin의 Property는 외부의 직접적인 접근을 막을 수 없습니다. 해당 Property가 인스턴스의 단순한 속성을 나타내는 것이라면, 성능을 위해서라도 특수한 형태의 접근자 메서드를 구현하지 않는 편이 더 좋겠지만, 우리는 언제나 “외부에서 수정해야 하지 말아야 하는(Unmodifable) 데이터”를 클래스에 담아냅니다.
또한 (Name-Based Destructing 파트에서 다루었듯이) Kotlin의 Collection Interface와 그 하위 Interface들은 Mutable한 것과 Immutable한 것, 두 가지의 형태를 가지고 있습니다(정확히는 Mutable한 클래스가 Immutable한 그것을 확장하는 구조입니다).
즉, 이러한 설계는, 온전히 그 데이터를 읽는 용도(Read-Only)로만 사용하는 경우와 그렇지 않은 경우를 엄격히 분리하여 Collection을 사용하라며, 개발자들에게 언어 차원에서 권장하는 것입니다. 이는 Kotlin 생태계의 리더(Leader)들이 가변 객체보다 불변 데이터를 취급하는 것을 선호하는 데 기인합니다.
아마도 코틀린 설계자들은 이 책의 저자들처럼 앞에서 소개한 '공유된 컬렉션을 변경하지 말라'는 관습에 익숙해서가 아닐까 생각한다. 파라미터로 받거나, 결과로 반환되거나, 다른 방식으로 코드 사이에서 공유된 컬렉션을 항상 불변 컬렉션으로 취급한다면, 가변 컬렉션이 불변 컬렉션을 확장하도록 타입 시스템을 설계하는 것이 상당히 안전하다. 여기서 '상당히'라는 말은 '완전히'가 아니라 '대부분'이라는 뜻이다. 어쨌든 이 경우 얻을 수 있는 이익이 비용보다 훨씬 더 크다.
덩컨 맥그레거, 냇 프라이스, 오현석 역,『자바에서 코틀린으로(Java to Kotlin: A Refactoring Guidebook)』(2021), 한빛미디어, 2022, p.105 ㄴ 볼드체로 표기된 텍스트는 인용서의 저자가 강조한 부분입니다.
그리고 Side Effect를 막기 위해 공유된 컬렉션을 변경하지 말아야 합니다. 그러니 Kotlin으로 Class를 작성할 때에는, 그 내부에서만 가변적인 Data Structure를 다루고, 이를 밖으로 내보낼 때에는 Immutable한 형태로 변경할 필요가 있습니다. Property의 Getter(Accessor) 메서드는, Customize한다 해도 그것의 Return Type까지 변경할 수는 없으므로, 우리에게는 캡슐을 구성할 새로운 규칙이 필요합니다. 이를 Kotlin에서는 Backing Property Pattern으로 정의합니다.
변경 가능한 Collection의 접근 제한자를 private으로 설정하고, 외부에서 접근 가능한 property를 val로 선언해 둔 방식입니다.
여기서, 같은 데이터를 가리키는데도 불구하고, 필연적으로 생성되는 Boilerplate(A Backing Property)는 일종의 '캡슐화의 부작용'입니다.
Kotlin의 Mission은 분명 “Boilerplate를 제거하는 것(To get rid of boilerplate)”이었습니다. 그들의 사명이 이런 곳에서도 예외를 발생시킬 수 없기에, 커뮤니티는 새로운 방식을 고안해 냅니다. 바로 감춰져 있던 Field를 밖으로 내보이는 것입니다. 그렇게 Boilerplate가 사라진 새로운 코드는 Property의 두 가지 측면을 ’내보이게’ 되는데요.

1. ( KEEP 문서의 설명처럼) 읽기 전용(Read-Only)인 Data Structure 만을 밖에 노출시킨다.
2. 클래스 외부로 Expose되는 타입과, 클래스 내부에서 다루어지는 (대부분의 경우 Modifiable한) Data Structure나 Type을 병기한다.
1번의 경우, 영어로는 Expose라는 표현이 적확할 것입니다. 클래스 내부에서 Mutable하게 다루어지던 Data Structure를 읽기 전용으로 밖에(Ex)-위치시키는(Pose) 것이니까요.
2번의 경우, 프로퍼티의 Field가 클래스 내부에서 ”어떤 타입으로 존재“하는지 명시하는 것입니다. 이는 하나의 프로퍼티가 동시에 두 가지 타입, 즉 Read-Only 타입과 Modifiable한 타입으로 선언될 수 있도록 합니다. (이를 명시적으로 표현하지 않는다면, Class 내부에서 다뤄지는 Field의 타입과 Expose되는 타입이 다르다는 사실을 컴파일러가 확인할 방법은 존재하지 않습니다.)
With this new syntax, you can explicitly declare the type and the value of the private backing field for your public property. No more boilerplate. Most of the design and the actual implementation for this new feature is already there. It's just waiting to be released shortly after Kotlin 2.0.
이 새로운 문법을 통해, Public한 Property가 가진 Private한 Backing Field의 값과 타입을 명시적으로 선언할 수 있게 되었습니다. 더 이상의 Bolierplate는 없습니다. 새 기능에 대한 디자인과 실제 구현은 마무리 단계에 있습니다. 이는 Kotlin 2.0의 첫 릴리즈 직후 공개될 예정입니다.
Kotlin Conf'23 컨퍼런스 키노트에서 - Roman Elizarov
작지만, 큰 도움을 주는 기능(small yet very helpful feature). Explicit Field가 객체지향 개발과 캡슐화에 있어 Kotlin 생태계의 새로운 표준이 될 날이 얼마 남지 않았습니다.
✍️ Wrap-Up
[8] One of the main ideas behind Kotlin is being pragmatic, i.e., being a programming language useful for day-to-day development, which helps the users get the job done via its features and its tools. Thus, a lot of design decisions were and still are influenced by how beneficial these decisions are for Kotlin users.
Kotlin의 핵심 가치는 "실용주의"입니다. 이는 Kotlin이 개발자들의 일상 속에 자연스레 녹아나는 언어가 되는 것, 즉 Kotlin이라는 생태계가 제공하는 기능과 도구를 통해 하루하루의 문제를 차근차근 해결해 나갈 수 있도록 돕는 것입니다. 그러므로, 우리의 많은 디자인 원칙은 Kotlin 사용자들에게 얼마나 도움을 줄 수 있는가를 기준으로 결정됩니다. 언제나 그랬듯이 말이죠.
이 글은 (논문을 제외한 일반적인 형태의 기술적 텍스트보다는 조금 많이) 긴 여정을 통해 Kotlin의 과거, 현재 그리고 미래 모두를 아우르는 (글쓴이 나름대로) 방대한 시도였습니다. 하지만 우리 옆에 쌓인 모든 책이 그렇고, 우리가 지내는 방대한 계가 그렇듯이, Kotlin의 이야기도 하나로 압축됩니다. “일상에 녹아드는 언어가 되는 것.” 딱딱하게 이야기하면 실용주의라고 할 수 있겠네요.
우리가 세상을 바꾸기 위해 궁극적으로 행해야 하는 일은, 어디엔가의 누군가를 수단으로 취급하는 과정이 들어간다면, 반드시 중지되어야 합니다. 프로그래머가 하는 일도 마찬가지입니다. 프로그래밍에서 우리가 사용하는 수많은 도구들과 함께 언어(Language)는 예외로 취급되어 왔지요. 하지만 이러한 생태계를 구축하기 위해 흘렸던 땀만큼은 우리의 빛나는 일에 수단으로 대우받지 않기를 바랐습니다.
그러니 이 글은 Kotlin에 대한 커다란 헌사라고 할 수 있겠네요. 수많은 개발자의 노력을 하나의 맥락으로 묶어내는 일, 그럼으로써 수단이 아닌 가치에 봉사하는 일. 이 공간에서의 작업은 온전히 여러분에게 그러한 의도가 전달될 수 있도록 최선을 다하겠습니다.
🧭 Reference
-
[1]
Nathaniel J. Smith, "Notes on structured concurrency, or: Go statement considered harmful", njs blog, last modified April 25, 2018.
[2]
Edsger W. Dijkstra. (1972). Chapter I: Notes on structured programming. In Structured programming. Academic Press Ltd., GBR, (pp. 10).
[3]
"By Default, the Kotlin/JVM compiler produces Java 8 compatible bytecode. (...) Starting with Kotlin 1.5, the compiler does not support producing bytecode compatible with Java versions below 8", Kotlin FAQ - Which versions of JVM does Kotlin target?에서 인용.
[4]
"When targeting JavaScript, Kotlin transpiles to ES5.1 and generates code which is compatible with module systems including AMD and CommonJS.", Kotlin FAQ - What does Kotlin compile down to?에서 인용.
[5]
Beuke, F. (2023). GitHut 2.0: GitHub Language Statistics.
https://madnight.github.io/githut/#/pull_requests/2023/3/Kotlin,Swift
https://madnight.github.io/githut/#/issues/2023/3/Kotlin,Swift
[6]
Aho, Alfred Vaino; Lam, Monica Sin-Ling; Sethi, Ravi; Ullman, Jeffrey David (2006). Compilers: Principles, Techniques, and Tools (2 ed.). Boston, Massachusetts, USA: Addison-Wesley. ISBN 0-321-48681-1. OCLC 70775643
[7]
Ali Dehghani, "Varargs and Spread Operator in Kotlin", Baeldung Kotlin, last modified May 9, 2023.
[8]
Marat Akhin, Mikhail Belyaev et al. (2020). Kotlin language specification: Kotlin/Core., JetBrains / JetBrains Research.